
Phân tích kỹ thuật nhân CPU trên Intel Meteor Lake-Không dành cho windows 10?
Dù Meteor Lake (MTL) là một chip đa thành phần (SoC), thì sức mạnh CPU vẫn là “linh hồn” của một hệ thống PC. Ở bài viết này, chúng ta sẽ phân tích sâu hơn kiến trúc P-Core Redwood Cove và E-Core Crestmont nằm trên con chip mới nhất của Intel, vừa có màn ra mắt hoành tráng ở triển lãm CES 2024 hồi đầu năm.
Trước hết, vấn đề Windows 10 (trở về trước) không phải mới xuất hiện từ MTL. Khi Intel chuyển sang dùng thiết kế hybrid (lai) tương tự big.LITTLE của ARM thì nó đã không tương thích với kernel (nhân) của Windows 10. Trên thực tế, việc Microsoft ra mắt Windows 11 có nguyên nhân sâu xa từ Intel. Nếu không phải do Intel “tác động”, Microsoft có lẽ vẫn chần chừ khi từng “mạnh mồm” tuyên bố Windows 10 sẽ là bản Windows cuối cùng.
Những con chip Core thế hệ 12 (Alder Lake hay ADL), thế hệ 13/14 (Raptor Lake hay RTL) và giờ là Core Ultra (MTL) đều đã có mặt ở đây. Thế là phóng lao phải theo lao, Windows 11 cũng thế mà ra đời thôi. Giờ đây, chúng ta còn nghe phong thanh về việc Windows 12 sẽ xuất hiện đâu đó trong 2024, nhưng đó sẽ là một câu chuyện khác (đằng nào thì bản cập nhật kế tiếp cũng chưa mang mác Windows 12).

Nếu là một người mê “nghịch” máy tính, chắc bạn cũng từng thử vọc vạch cài qua Windows đôi ba lần. Hẳn nhiên bạn sẽ thấy vấn đề Windows 10 trên ADL, RTL (và mới đây là MTL) không quá “nghiêm trọng” như truyền thông vẫn nói. Mấy con chip trên vẫn chạy tốt với Windows 10, bạn vẫn dùng được bình thường. Vậy thì cái vấn đề ở đây là gì?

Về cơ bản Windows 10 (và các bản trước) vốn không được thiết kế để phân biệt nhiều kiến trúc CPU khác nhau trên cùng một hệ thống. Bạn cấp cho nó bao nhiêu nhân, nó sẽ “ngốn” hết bấy nhiêu nhân, không phân biệt đời cũ hay đời mới, to hay nhỏ, mạnh hay yếu. Do đó trên thực tế, bạn vẫn dùng Windows 10 được bình thường với các thiết kế hybrid của Intel, nhưng nó sẽ không-tối-ưu hoặc không-khai-thác-tốt.
Trong một vài trường hợp, hiệu năng trên Windows 10 thậm chí còn bị tụt đi do kernel của OS này “đùn” việc cho các nhân yếu làm. Đã từng có thủ thuật “tắt” bớt các nhân E-core trong BIOS để Windows 10 không bị tụt hiệu năng do đặc tính này! Nhưng nhìn chung mua CPU mới về để tắt bớt E-core đi thì… thà mua AMD cho rồi…

Nên để khai-thác-hiệu-quả kiến trúc hybrid, buộc lòng Microsoft phải ra mắt OS mới, và nhiệm vụ của Windows 11 (trở về sau) là phải “hiểu” thêm một thành phần mới của Intel – Thread Director. Chức năng của Thread Director là nó sẽ nằm giữa OS kernel và các nhân CPU nhằm điều phối công việc. Trước đây nhân nào nhận tác vụ nào sẽ do OS kernel quản lý còn từ nay, mọi thứ phải thông qua Thread Director. Đây có lẽ cũng là một phần lý do mà lúc mới ra mắt, hiệu năng Windows 11 trên các chip Zen của AMD “trồi sụt” vì bên AMD không có thiết kế này.
Nhưng nếu Windows 10 vẫn có thể dùng trên MTL thì lại trở về câu hỏi, vấn đề của hôm nay là gì? Đó là khác với ADL hay RTL, Thread Director trên MTL không chia việc theo kiểu từ P-core trở xuống (E-core có tồn tại hay không không ảnh hưởng) mà từ E-core trở lên (E-core bắt buộc phải có). Thậm chí vấn đề tệ hơn khi MTL có tới 3 cấp core – LP E-core trên SoC (nhận việc đầu tiên), E-core và P-core trên die CPU. Có nghĩa bạn không thể “tắt” chúng đi như đã từng làm trên ADL hay RTL. Vậy nên nếu “cố chấp” với Windows 10, người bị tổn thương sẽ chính là bạn…


Trở lại với chủ đề chính, trong ngày ra mắt MTL, Intel đã tuyên bố “đây là cuộc cách mạng chip lớn nhất 40 năm qua của hãng”. Do đây là lần đầu tiên công ty này lấy trọng tâm thiết kế nằm ở die SoC, chứ không phải die CPU. Mọi tác vụ đầu tiên sẽ được xử lý tại SoC, sau đấy mới được “phân phối” tới từng die chức năng riêng biệt. Chi tiết đáng chú ý là ngay trên die SoC sẽ có sẵn 2 nhân E-core tiết kiệm điện. Khi 2 nhân này “bị đuối”, chúng sẽ chuyển công việc lên cho die CPU ở tuyến trên. Chúng ta hãy bắt đầu với nhân P-core Redwood Cove.
Thực tế mà nói, Intel không nói gì nhiều về P-core này, ngoại trừ một slide rất sơ sài với cái tên và vài dòng chữ vô vị… May thay, ảnh chụp diagram Redwood Cove cho thấy nó… y chang như Golden Cove (ADL) hoặc Raptor Cove (RTL). Dựa vào những gì chúng ta biết thì Raptor Cove chỉ là bản refresh của Golden Cove trong đó L2 Cache tăng lên 2 MB (so với 1.25 MB của đời trước). Khác biệt chính ở đây là ADL/RTL được xây dựng trên tiến trình 10 nm (hoặc Intel 7), còn die CPU MTL là 7 nm (hoặc Intel 4).

Do đó tuy không chắc chắn 100%, nhưng ta có thể tạm kết luận Intel vẫn dùng lại kiến trúc P-core có trên RTL cho MTL. Và trong trường hợp bạn chưa biết P-core của dòng chip Core thế hệ 13/14 như thế nào, thì chúng ta hãy vào cuộc.
Về căn bản, một kiến trúc CPU phổ thông sẽ có 3 phần – front-end, execution và back-end. Quá trình làm việc tương tự như bạn đặt mua một món hàng qua mạng. Ở front-end, sau khi nhận được yêu cầu của bạn, hệ thống sẽ lên đơn để đưa vào danh sách chờ. Tới execution, cửa hàng nhận đơn từ hệ thống, bắt đầu quá trình kiểm tra xem hàng còn không, nguyên liệu còn không, nhân lực phù hợp có không… bắt đầu việc xử lý để ra món hàng mà bạn yêu cầu. Xuống back-end, món hàng mà bạn đặt đã hoàn tất và được chuyển qua bộ nhận giao nhận để gửi tới tay bạn.
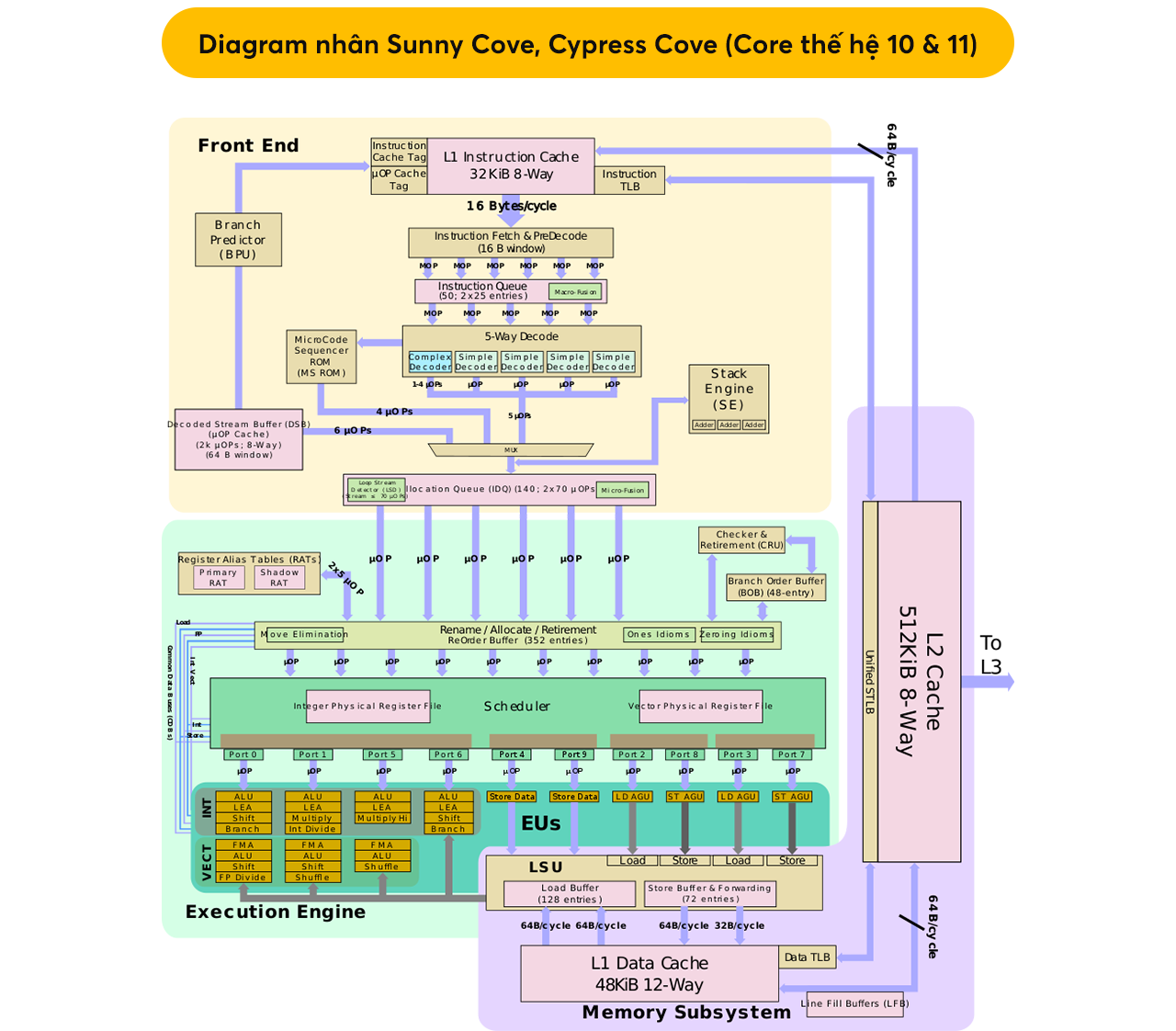

Với Golden Cove, nó là một sự thay đổi lớn về kiến trúc so với thế hệ trước đó (Sunny Cove/Cypress Cove). Trước hết, ở front-end, bộ phận decode các tập lệnh được mở rộng thành 6-wide (so với 4-wide ở thế hệ cũ). Đối với kiến trúc x86, bước đi này khá táo bạo vì với đặc trưng độ dài các tập lệnh biến thiên, nó tương đối phức tạp hơn các kiến trúc RISC (ví dụ ARM) khi muốn mở rộng decoder. Nếu không thiết kế kỹ càng, việc mở rộng decoder x86 có thể bị “phản dam” khi làm giảm hiệu năng chip. Có thể nói thêm là cả 4 thế hệ kiến trúc Zen bên AMD vẫn áp dụng 4-wide decoder. Theo một số tin đồn thì Zen 5 có thể sẽ thay đổi triết lý trên, nhưng đó sẽ là một câu chuyện khác nữa.
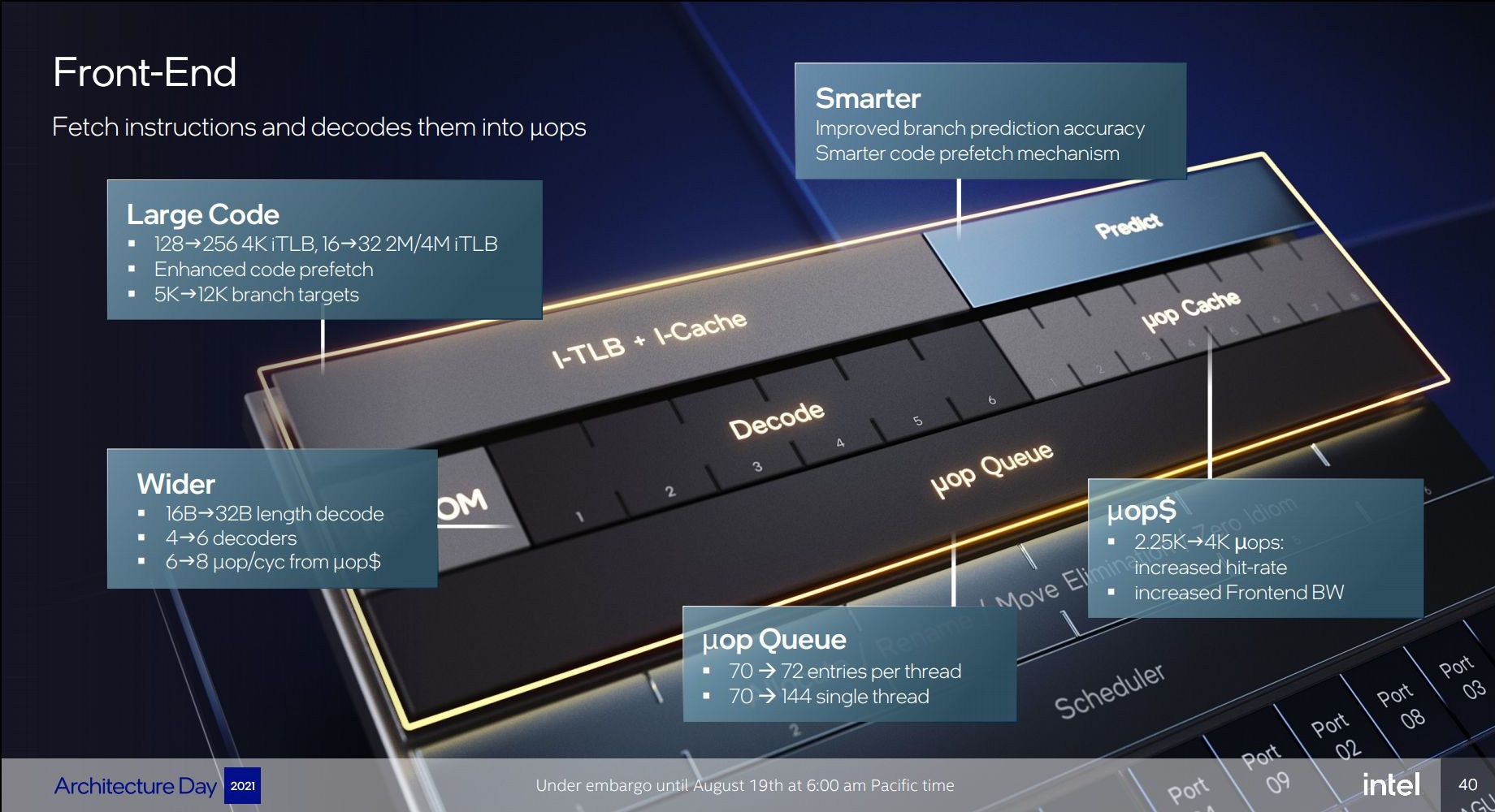
Tất nhiên mở rộng decoder sẽ vô nghĩa nếu các thành phần hỗ trợ nó không được cải tiến theo. Cụ thể iTLB hỗ trợ tới 256 entry (tăng từ 128) các tập lệnh 4K, hoặc 32 entry (tăng từ 16) với các tập lệnh 2M/4M. Riêng dung lượng I-Cache trên Redwood Cove được tăng lên 64 KB (Golden Cove chỉ có 32 KB). Vai trò của µOP Cache cũng “nặng nề” hơn khi nó đóng vai trò “giảm tải” điện năng khi decoder được mở rộng. Intel cho biết 80% thời gian làm việc của decoder là “ngắt mạch” (gated) do phần lớn các vi lệnh được lấy ra từ µOP Cache. µOP Cache trên Golden Cove có thể chứa tới 4K entry (tăng từ 2250), cho phép đạt năng suất 8 vi lệnh/chu kỳ (tăng từ 6). Mục đích là để tăng hiệu suất decode 16 byte/chu kỳ lên 32 byte/chu kỳ. Tất cả các tập lệnh được “xé lẻ” thành vi lệnh sẽ được dồn xuống µOP Queue để chờ xử lý ở bước tiếp theo.
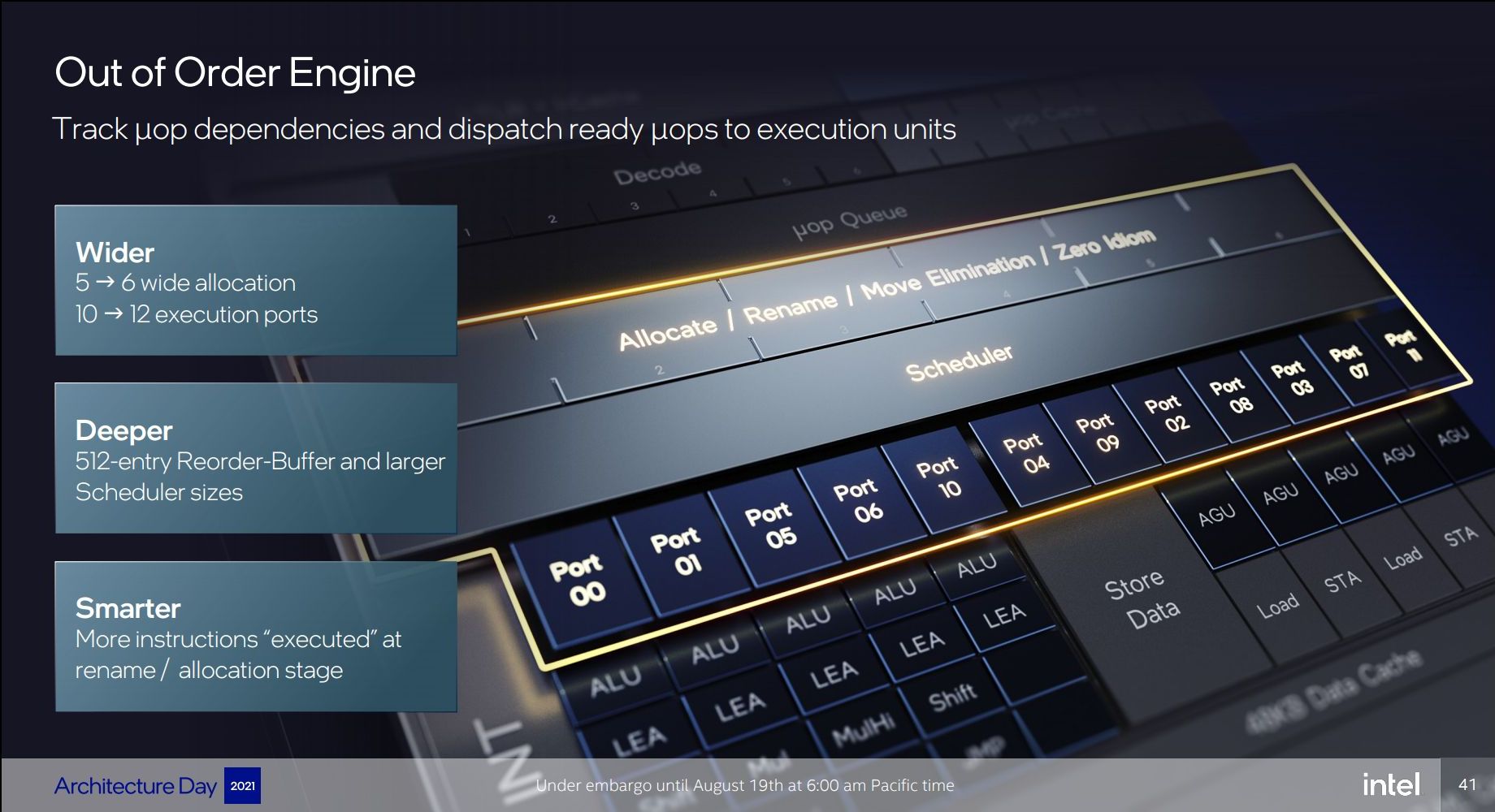
Và trước khi mọi thứ rời khỏi front-end để sang execution, Intel còn thêm một khu vực “đệm” dùng để phân loại, sàng lọc, đáng giá, sắp xếp các vi lệnh ở trên gọi là Out of Order Engine. Cần chú ý là Engine này cũng được mở rộng thành 6-wide (tăng từ 5). Nên trên lý thuyết, Golden Cove/Redwood Cove có thể đạt hiệu suất 6 IPC (kết hợp với 6-wide decoder), nhưng ở đây chúng ta dùng vi lệnh (µOP) thay cho tập lệnh (intruction).

Với phần front-end mở rộng nhiều đến thế, dĩ nhiên phần execution cũng không thể giữ nguyên như kiến trúc cũ được. Golden Cove có tới 12 pipeline xử lý số nguyên (tăng từ 10), trong đó 5 pipeline chuyên ALU (tăng từ 4) và 7 pipeline chuyên AGU (tăng từ 6). Có một chi tiết thú vị trong diagram Redwood Cove của Intel là pipeline 11 & 10 hoán vị cho nhau mà mình cũng không rõ có tác dụng gì (có thể bị là nhầm lẫn ở khâu đánh máy không chừng). Còn lại các chi tiết vẫn y hệt nhau.

Cũng cần chú ý thêm để đáp ứng đủ “đầu việc” cho 12 pipeline trên, kích thước bộ đệm re-order buffer (ROB) Golden Cove cũng phải tăng đáng kể tới 512 entry (tăng từ 352). Đây là con số cực kỳ lớn và có lẽ chỉ đứng sau các chip M của Apple (không khó hiểu vì kiến trúc ARM dễ mở rộng hơn so với x86). Bộ đệm này cũng là thành phần sẽ gửi việc các đơn vị xử lý số thực (FPU) nằm sát cạnh các đơn vị số nguyên (INT). Nhưng khác với INT, FPU trên Golden Cove không được tăng thêm số pipeline. Chúng chỉ được bổ sung thêm tính năng FADD (so với Sunny Cove), hỗ trợ tập lệnh AVX-512 cùng với toán tử FP16 dùng trong thuật toán AI. Thanh ghi FPU cũng được tăng lên 332 entry (tăng từ 224) để đáp ứng các thay đổi trên.

Sự thiên vị INT so với FPU này cũng dễ hiểu vì thiết kế INT đơn giản và tốn ít silicon hơn FPU. Chưa kể FPU hay được dùng cho các ứng dụng cao cấp như HPC hay siêu máy tính, còn INT thường gặp trong đời sống hàng ngày hơn.

Từ 2 phần front-end lẫn execution trên, không khó để thấy back-end Golden Cove cũng phải được mở rộng thêm để có thể “chứa” được hết lượng dữ liệu phát sinh trên kiến trúc mới. Nếu như Sunny Cove chỉ có 2 cổng Load dữ liệu thì con số này trên Golden Cove là 3 cổng (số cổng Store vẫn là 2). Với các tập lệnh liên quan tới dữ liệu 256-bit, mỗi chu kỳ cho phép đạt tới 3 lần Load. Còn với dữ liệu AVX-512, hiệu suất là 2 lần Load/chu kỳ.


Về mặt cache, dung lượng L1 không thay đổi so với thế hệ cũ, ở mức 48 KB. Trong khi đó L2 Cache tăng vọt lên 1.25 MB (Golden Cove) hoặc 2 MB (Raptor Cove/Redwood Cove) so với con số “khiêm tốn” 512 KB (Sunny Cove). Sự gia tăng đáng kể kích thước L2 Cache thậm chí ngay giữa Golden Cove với Raptor Cove cho thấy với sự thay đổi cơ bản từ 4 IPC lên 6 IPC đã phát sinh ra nhiều dữ liệu như thế nào và phần back-end buộc phải “chạy đua” thì mới có thể “theo kịp” front-end lẫn execution.
Ngoài ra, bên cạnh những tập lệnh vốn có sẵn trên Sunny Cove, Golden Cove còn bổ sung thêm các tập lệnh khác như AVX-VNNI, AVX512-FP16, TSX. Do Intel không đề cập gì khác với Redwood Cove, có thể hiểu MTL cũng như giữ nguyên các tập lệnh giống ADL hoặc RTL.
Dài rồi, mình sẽ có thêm nội dung khác về E-core Crestmont và E-core Gracemont sau.
Nguồn: Tinhte.vn