
Phân tích kiến trúc vi xử lý Intel Lunar Lake – Phần 3: Thread Director mới và NPU4
Cơ chế Thread Director mới – 8 nhân như 4 nhân?
Ở bài trước, chúng ta đã biết LNL (đúng hơn là Lion Cove) sẽ không có SMT. Lý do Intel đưa ra là 1 nhân P-core được-tối-ưu sẽ xử lý công việc hiệu quả hơn khi chạy SMT. Nhưng quan điểm của mình cho rằng đấy không phải nguyên nhân chính. Mà “kẻ tội đồ” ở sau tất cả chính là TD.
Cơ chế TD trên Raptor Lake là nguyên nhân làm crash?
Về chức năng của TD hẳn bạn cũng đã biết nó là thành phần nằm giữa OS và con chip, chủ động phân tích các yêu cầu của ứng dụng để xem E-core hay P-core sẽ tối ưu hơn khi xử lý công việc nào đó (luồng). Nhưng TD cũng chính là điểm mà mọi thứ trở nên rối rắm. Hẳn bạn từng nghe chuyện nhiều máy tính chạy Core đời 13/14 bị crash? Có nhiều lý do được nêu ra nhưng theo ý kiến của mình, vấn đề nằm ở chỗ TD liên tục luân chuyển luồng công việc qua lại giữa E-Core và P-core. Do kiến trúc và cách xử lý khác nhau, quá trình luân chuyển này khiến cho OS/ứng dụng không nắm được dữ liệu chúng đang cần ở đâu và ở tình huống tệ nhất là mọi thứ crash.
Nó cũng gần tương tự việc bạn đặt hàng ở Quang Trung nhưng shipper lại đọc thành Nguyễn Huệ, hoặc bạn chờ ở Đinh Tiên Hoàng nhưng người yêu lại tới Đinh Bộ Lĩnh. Bạn ghi là QL1A nhưng ở tỉnh thành nào thì không có…
Cách TD phân loại công việc
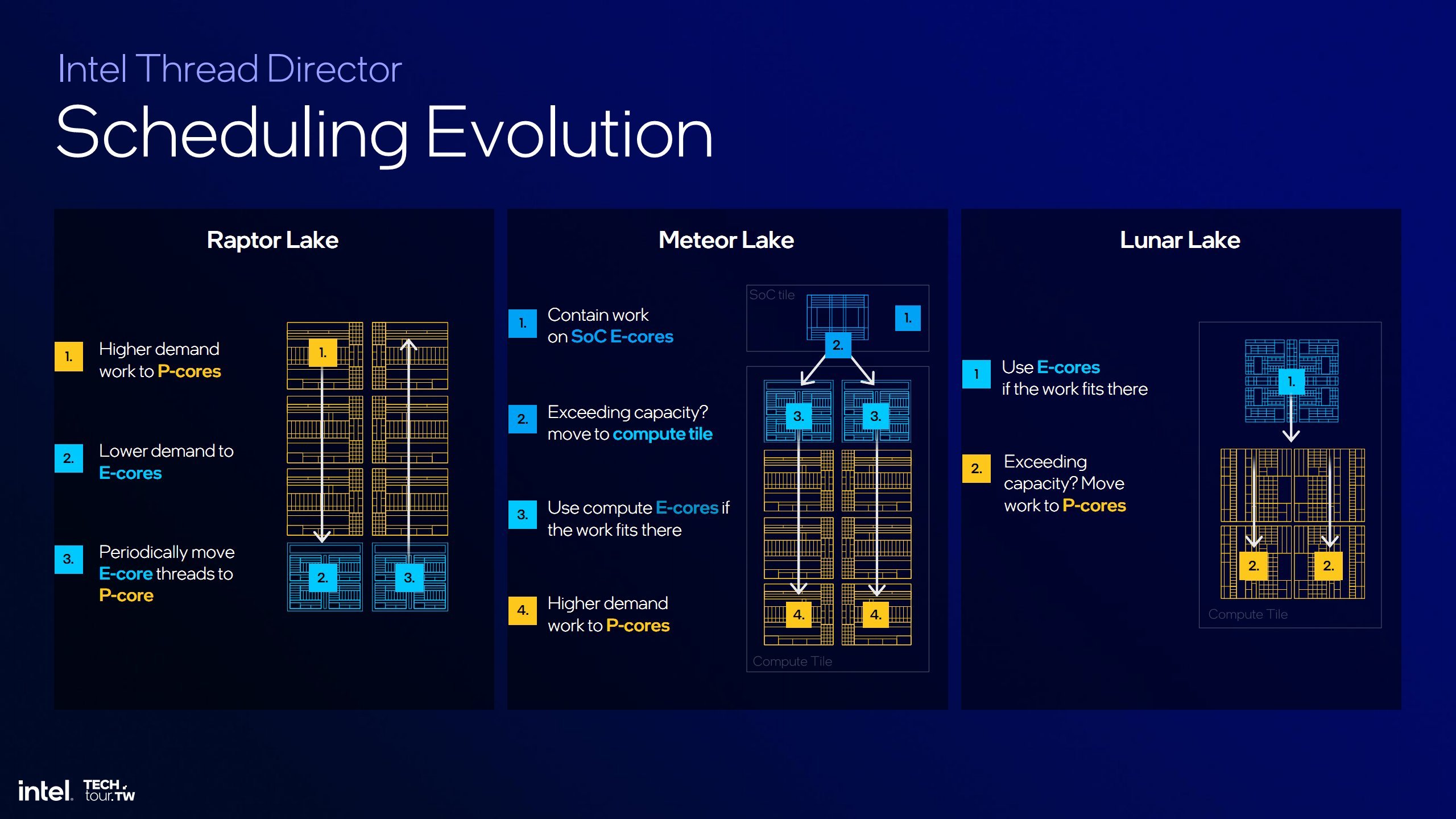
Tới đời MTL, Intel đổi lại cách TD làm việc. Thay vì luân chuyển mọi thứ kiểu ngẫu hứng, nay E-core sẽ đảm nhận trước tiên. Chỉ khi yêu cầu tính toán nhiều mới chuyển lên P-core (không có chiều ngược lại). Cách làm này trên lý thuyết sẽ không gây ra tình trạng shipper một nơi, khách một nẻo như trước. Có điều MTL chỉ tồn tại trên laptop nên chúng ta chưa kiểm định được rõ ràng mọi tình huống.
Và kế đến là LNL, Intel lại… đổi tiếp!
Nhìn từ xa thì TD của LNL vẫn làm việc giống như MTL – vẫn E-core trước mới qua P-core. Tuy nhiên khi xem xét chi tiết hơn, quá trình luân chuyển này tương đương 1 E-core = 1 P-core – đây chính là mấu chốt. Ở MTL trở về trước, P-core hỗ trợ SMT cho phép xử lý 2 luồng công việc khác nhau, nhưng E-core chỉ duy nhất 1 luồng. Vậy với 8 E-core hay 8 luồng và 6 P-core hay 12 luồng, quá trình luân chuyển sẽ diễn ra thế nào? Tất yếu sẽ có P-core nhận tới 2 luồng từ E-core và P-core chỉ nhận 1 luồng. Đây là cách phân chia công việc không hiệu quả.


4 luồng E-core sẽ có 4 luồng P-core “gánh team” khi cần

Lúc chạy toàn việc nhẹ thì chỉ có 4/8 nhân làm việc
Bù lại, căn cứ theo cách làm việc này, nếu máy tính chỉ đang chạy duy nhất công việc nặng, thì gần như chỉ có 4 P-core hoạt động. Và khi máy ở chế độ nhàn rỗi, cũng chỉ có 4 E-core làm việc. Chỉ khi cùng làm cả việc nặng nhẹ (hoặc nhiều việc vừa phải) thì cả 8 nhân mới phát huy hết. Nên nhìn theo cách nào đấy LNL giống như một CPU 4(+) nhân hơn là 8 nhân. Tất nhiên, đây là cách nhìn của riêng mình, bạn có thể nhìn khác.
NPU4 – Thừa sức cho Copilot+ PC
10 năm trước nếu nói về AI cá nhân hẳn nhiều người sẽ bật cười, vì dữ liệu còn rời rạc và thuật toán còn sơ khai, mang chúng lên PC không có ý nghĩa thực tế nào. Nhưng nay là 2024, nhiều thứ đã thay đổi. AI đã hiện diện ở rất nhiều nơi và AI cá nhân đang dần trở thành một tiêu chuẩn chung. Cả AMD, Intel và Qualcomm đều dùng AI để quảng cáo cho sản phẩm của mình. Nhưng MTL lẫn Ryzen Mobile 7000/8000 đều chưa đủ “mạnh” theo yêu cầu của Microsoft.

Lịch sử phát triển NPU của Intel
Logic mà nói, Intel không thể chỉ sau một đêm là có thể úm ba la một khối ASIC chỉ chuyên AI có năng lực tính toán tới 48 ngàn tỷ phép tính mỗi giây (TOPS) được. Công ty này bắt đầu đặt tay vô nghiên cứu NPU từ 2018. Nhưng 2 thế hệ NPU đầu tiên không được mang ra thị trường. Có thể hiểu vì thời điểm 2018 lẫn 2021, thị trường AI cá nhân chưa “chín muồi”. Mẫu NPU3 được đưa tới người dùng cá nhân vào năm ngoái trên MTL với năng lực 11.5 TOPS – tốt nhưng chưa đủ chuẩn Copilot+. Và nay là năm thứ 6, một chặng đường tương đối vừa đủ cho một dự án R&D trưởng thành.

So sánh NPU3 và NPU4
Do NPU1 và NPU2 chưa bao giờ được công bố, nên chúng ta cũng không cần nhắc tới chúng. NPU4 trên LNL của hôm nay là sự kế thừa từ NPU3 trên MTL. Về cơ bản cấu trúc, NPU4 vẫn giữ nguyên như NPU3, chủ yếu là số lượng đơn vị chức năng của nó nhiều hơn đàn anh. Từ 2 khối NCE (Neural Compute Engine), nay chúng ta có 6 khối. Và nhìn từ trên cao, toàn bộ khối NPU4 nhìn… rất quen.
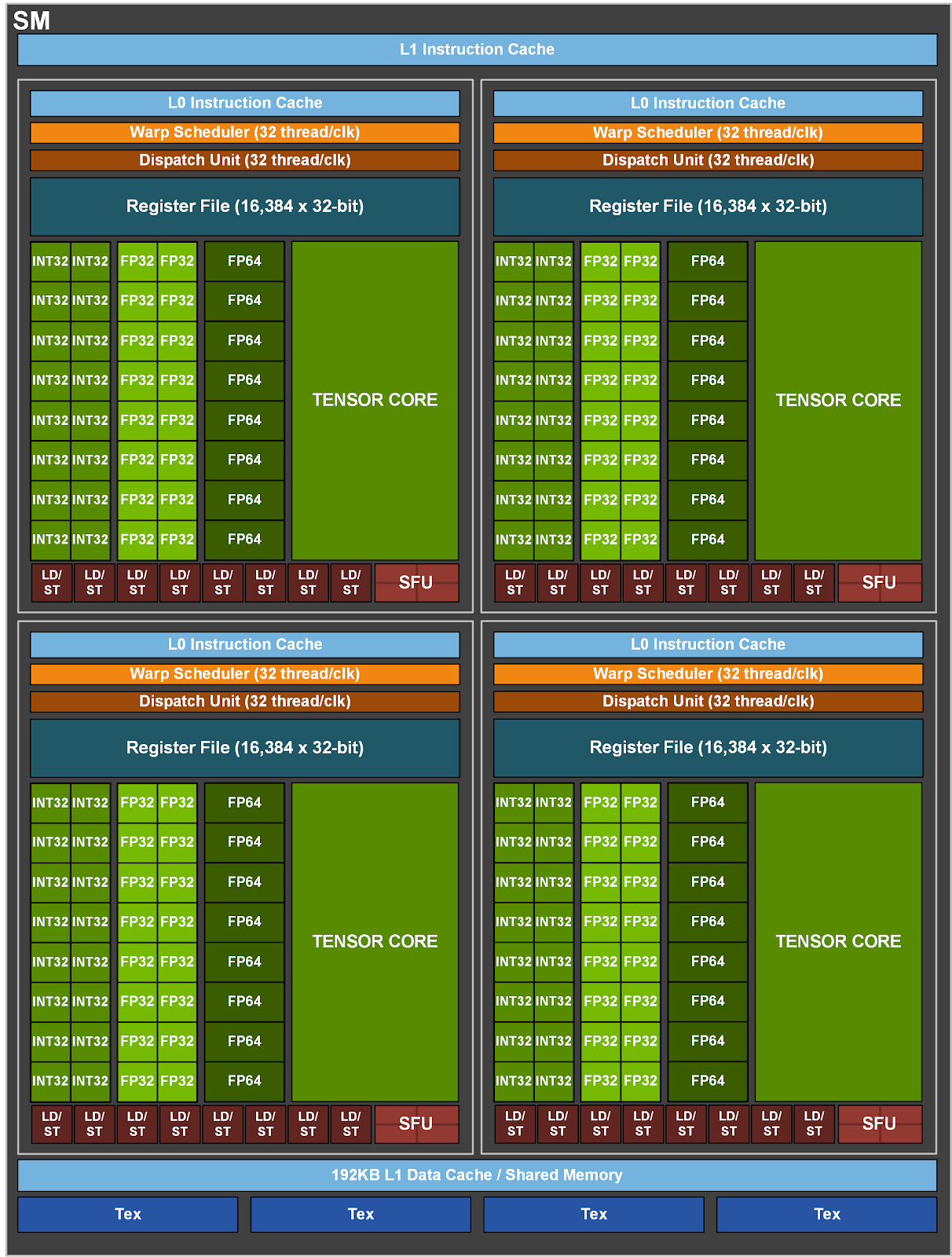
Sơ đồ khối SM trên GPU NVIDIA A100
Vâng, cấu trúc NPU4 của Intel nhìn không khác GPU của NVIDIA là bao, với các NCE tương tự các SM. Sự tương quan này âu cũng là điều dễ hiểu vì cấu trúc của GPU nói chung hầu hết là các SIMD để xử lý vector. Sự xuất hiện của AI đặt thêm vấn đề nhân ma trận dẫn tới sự xuất hiện của các khối MAC (nhân/chồng dữ liệu). Vì thế sự xuất hiện các mảng MAC gần như là sự tiến bộ lên từ các SIMD. Đây cũng là lý tại sao nhân CPU chạy AI rất dở vì chúng đa phần thực hiện phép tính vô hướng (scalar), còn GPU là tính vector, và mạng neuron là nhân ma trận. Việc NVIDIA bổ sung thêm nhân Tensor hay Intel có thêm bộ mở rộng XMX cho GPU Xe chính là để giải quyết bài toán ma trận này. Thế nên bạn đừng ngạc nhiên khi nhân đồ hoạ của LNL có năng lực AI tới 67 TOPS, hơn cả NPU4.

GPU là những cỗ máy xử lý vector, nâng cấp nhân ma trận dễ dàng hơn CPU
Song GPU là để xử lý đồ hoạ. Trừ phi nhu cầu vẽ ảnh 2D/3D của bạn là zero thì GPU mới “toàn tâm toàn ý” để xử lý AI. Còn khi đang chơi game mà bạn bắt GPU “gánh” cả AI thì có phần hơi áp lực. Thế nên sự tồn tại của một khối ASIC chuyên AI vẫn hơn.
Bên trong 1 NCE, có 2 thành phần chính là SHAVE DSP để xử lý toán vector và Inference Pipeline chuyên cho nhân ma trận. So với SHAVE DSP của NPU3, SHAVE DSP trên NPU4 có kích thước lớn gấp 4 lần, với thanh ghi tăng từ 128-bit lên 512-bit, cho phép 1 chu kỳ tính toán đạt hiệu suất 32 vector FP16 (trước là 8 vector). Còn Inference Pipeline vẫn giữ nguyên so với thế hệ trước. Mỗi mảng MAC vẫn có hiệu suất 2048 phép toán INT8/chu kỳ hoặc 1024 phép toán FP16/chu kỳ.

Cấu trúc mảng MAC trên NPU4 vẫn như NPU3

Riêng SHAVE DSP của NPU4 mạnh gấp lần thế hệ cũ
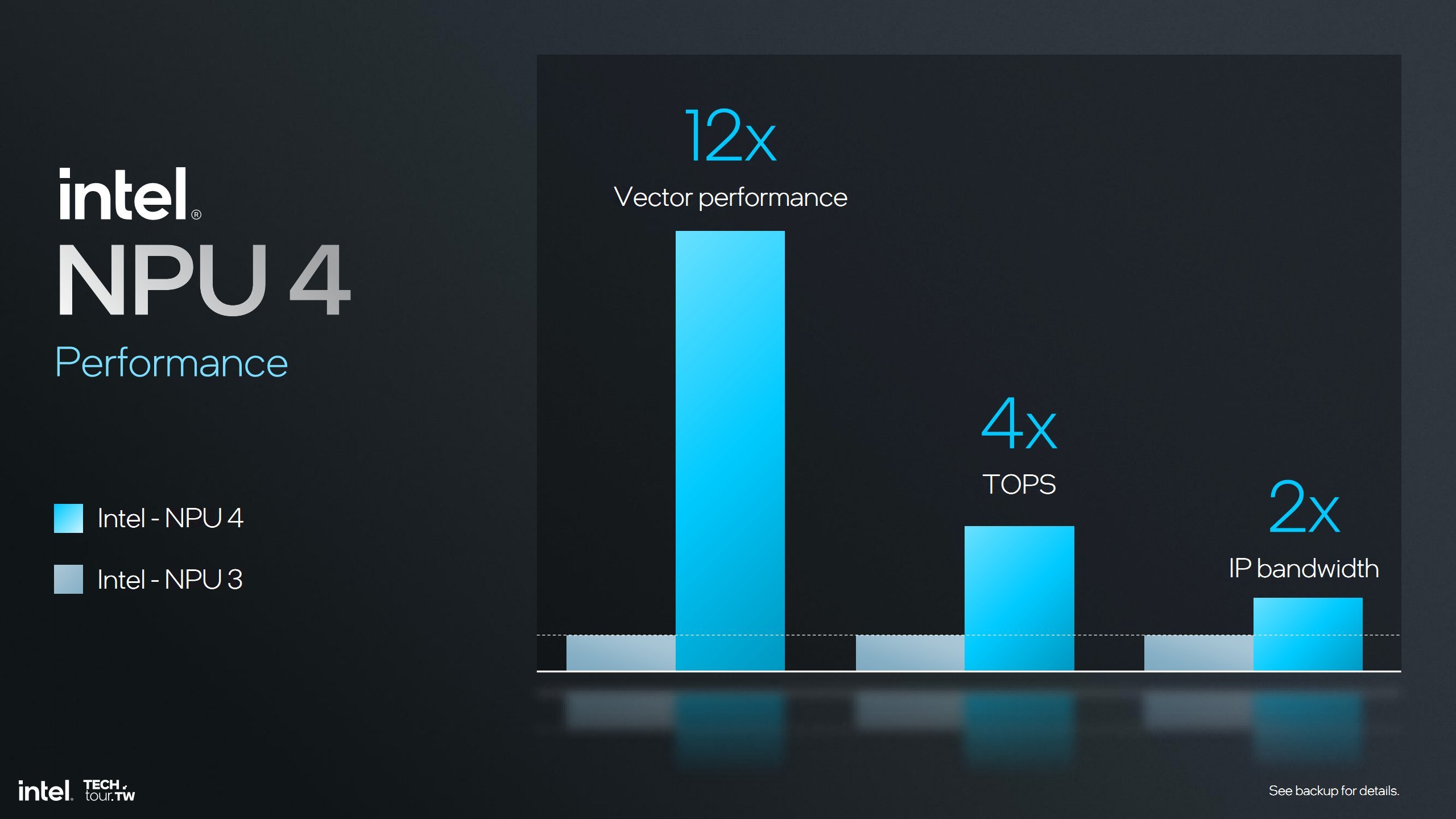
So sánh hiệu năng AI giữa NPU3 và NPU4
Đáng giá chung, Intel cho biết NPU4 có hiệu suất tính vector gấp 12 lần NPU3 (cũng hợp lý vì SHAVE DSP được cải tiến nhiều nhất), hiệu năng TOPS tăng 4 lần và băng thông dữ liệu tăng gấp đôi.
Khi người khổng lồ thức giấc
Chuyện gần như không cần bàn cãi là Intel đã có nhiều năm “ngủ quên” khi mỗi năm ra mắt một dòng chip Core mới nhưng hiệu năng gần như đứng yên. Đấy là giai đoạn khi Brian Krzanich làm lãnh đạo. Brian cũng rất chần chừ trong việc đầu tư vào EUV các kỹ sư Intel phải “đánh vật” với tiến trình 14 nm. Dòng chip Cannon Lake vốn được phát triển cho dây chuyền 10 nm sau cùng bị huỷ bỏ. Kiến trúc Sunny Cove được xem là thay đổi lớn nhất từ kiến trúc Core (2006, 65 nm) cũng “dính đạn” vì dây chuyền 10 nm chưa sẵn sàng để sản xuất. Nó đành trở về 14 nm với tên gọi Cypress Cove.

LNL được sản xuất trên dây chuyền TSMC N3B
Chỉ khi Pat Gelsinger làm CEO, các vấn đề cũ nát mới được xử lý công ty này không ngần ngại thuê TSMC để sản xuất nếu các dây chuyền sẵn có không thể đáp ứng. MTL lẫn LNL là 2 ví dụ (ARL có lẽ cũng thế). LNL dùng tiến trình N3B mới nhất (hiện có) và sẽ đối thủ nặng ký cho các sản phẩm của AMD lẫn Qualcomm.
Việc “nhảy cóc” lên 8-wide decoder cho thấy Pat sẵn sàng thay đổi “nếu cần thiết” để cạnh tranh với đối thủ. Và nếu các tin đồn về hiệu năng LNL mới đây là chính xác, thì chuyện đó âu cũng là hợp lý với các thay đổi trên Lion Cove. Đó là nền móng cho Intel trong ít nhất 3 năm nữa trên mảng PC. Vấn đề tồn tại tiếp theo là phiên bản desktop (ARL) sẽ có bao nhiêu nhân Lion Cove? Và nó sẽ mạnh tới mức nào khi không còn bị giới hạn TDP như trên LNL?
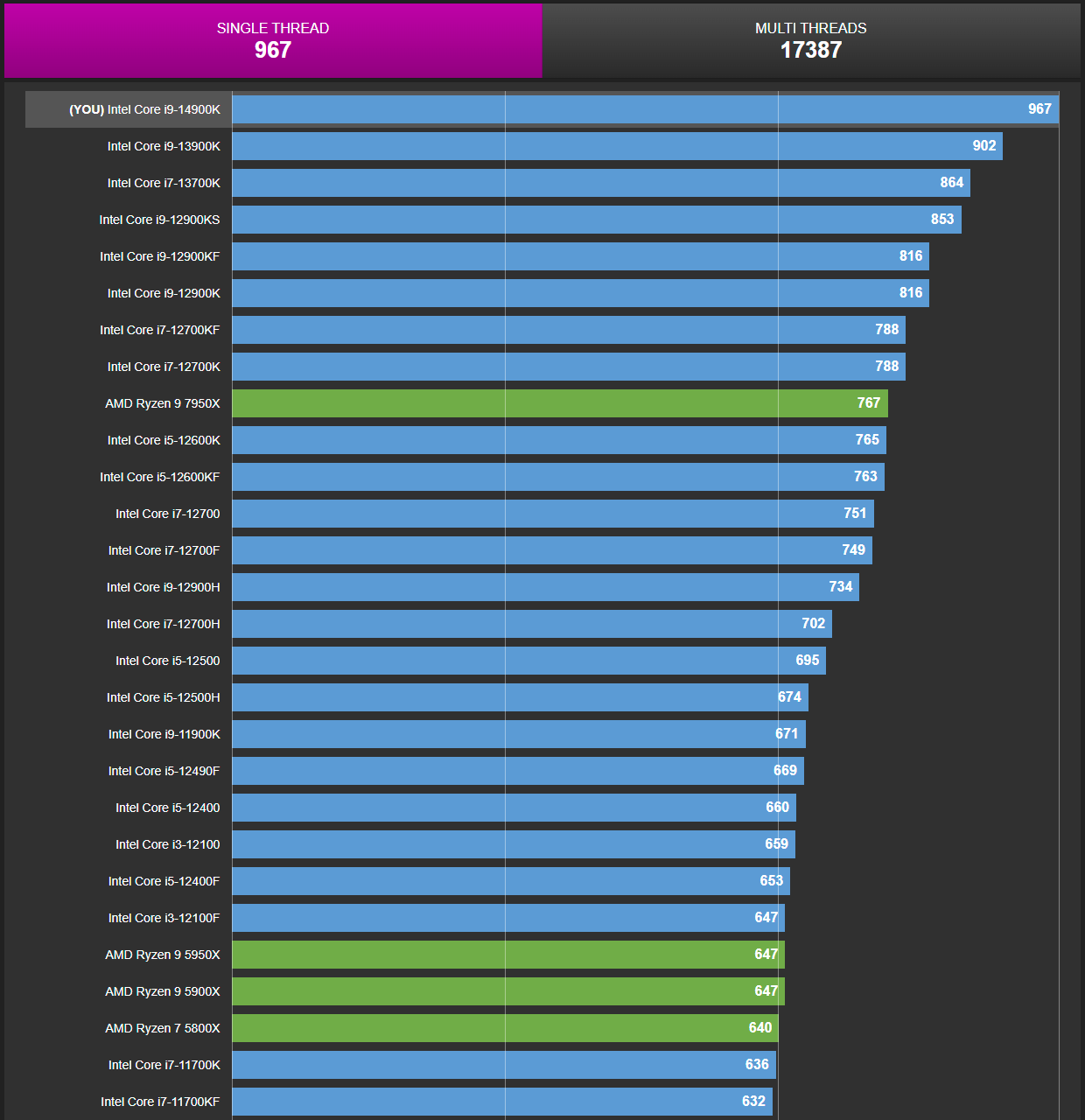
Hiệu năng đơn luồng của Raptor Lake vẫn cao hơn Zen 4
Riêng Skymont, điểm thú vị nhất với mình là hiệu năng khi kèm LLC/Ringbus. Vì LNL là thiết kế tiết kiệm điện, chúng ta sẽ không thấy được điều này. Nhưng ARL thì sao? Liệu Intel sẽ cho nó xài chung LLC như Lion Cove? Bạn cần chú ý các chip Core 13/14 hiện nay vẫn giữ ngôi đầu bảng hiệu năng đơn luồng, và nó đến từ Raptor Cove.
Với NPU, hiện tại chưa thể nói gì được nhiều về khối ASIC này, vì AI cá nhân vẫn là một tính năng mới. Thời gian dài chúng ta mới nhận xét được NPU của công ty nào hiệu quả hơn. Nhưng cá nhân mình cho rằng đa số sẽ chỉ xây dựng NPU đạt tiêu chuẩn Copilot+ chứ không làm mạnh hơn vì suy cho cùng, hiệu năng CPU/GPU vẫn là quan trọng nhất.