
Phân tích kiến trúc vi xử lý Intel Lunar Lake – Phần 1: “Nhảy cóc” lên 8-wide
Năm 2024 này dường như là một dấu mốc quan trọng trên thị trường vi xử lý toàn cầu, khi các đại diện ARM (RISC – Reduced Instruction Set Computer) đang tỏ ra thắng thế với những cái tên Apple và Qualcomm. Bản thân AMD tuy cũng khả quan hơn Intel nhưng với đặc trưng kiến trúc x86 (CISC – Complex Instruction Set Computer), tương lai về việc kiến trúc nào sẽ được giới công nghệ ưu ái là cuộc đấu trí mà mọi CEO các công ty chip sẽ phải đau đầu tính toán. Bản thân con chip Lunar Lake (LNL) được bàn trong nội dung này chỉ là một mảnh ghép về mặt lâu dài.
Sơ lược thị trường vi xử lý nhiều năm qua
Về cơ bản mà nói, cho tới 2015 trở về trước đó, có thể chia x86 và ARM ra 2 phân khúc máy tính (khổ lớn) và di động (cầm tay) hoặc thiết bị nhúng. Xu thế sản phẩm này dẫn tới kiểu suy nghĩ rập khuôn là x86 chỉ phù hợp với ai cần sức mạnh tính toán còn ARM chỉ dành cho tiết kiệm điện. Tư duy này không hẳn sai nhưng cho thấy sự hiểu biết không đầy đủ về bản chất x86 lẫn ARM.

Trên thực tế, x86 vẫn có thể tiết kiệm điện và ARM vẫn có thể dùng cho hiệu năng cao. Ví dụ điển hình như Intel Atom Z từng dùng trên một số mẫu smartphone Android nhiều năm trước. Tuy nhiên đáng buồn là nó đã không thành công do có 3 nguyên nhân chủ đạo. Trước hết là sự cạnh tranh quá gay gắt từ các đối thủ ARM, hầu như các thương hiệu smartphone Android phổ biến chỉ dùng chip Qualcomm, Samsung hoặc MediaTek. Sau đó là việc phải chạy giả lập vì nhiều ứng dụng Android chỉ được viết cho ARM, khiến cho hiệu năng bị tụt giảm. Cuối cùng là Intel không mạnh về hạ tầng viễn thông (Intel mạnh Wi-Fi, Bluetooth nhưng bước sang 2G/3G/4G là sân nhà của Qualcomm, Broadcom…). Kết cục là Atom Z bị “vùi dập tơi tả” vì không tạo ra được hệ sinh thái đủ mạnh trên di động.
Qua tới ARM, thực tế cho thấy kiến trúc này vẫn có thể cho sức mạnh cao khi cần thiết. Ví như siêu máy tính Fugaku của Nhật từng đứng đầu TOP500 vào 2020. Gần gũi hơn chúng ta có những con chip di động vẫn có hiệu năng cao như Apple dòng A hay Snapdragon, Tegra thế hệ 32-bit trở về sau. Tuy vậy cái giá để có hiệu năng cao cũng không khác x86 là bao – hao điện và toả nhiều nhiệt. Những thứ tưởng chừng là trò đùa cho smartphone như quạt tản nhiệt bỗng trở thành một sản phẩm tiêu dùng đàng hoàng. Cũng vì thế mà ARM buộc phải cho ra kiến trúc big.LITTLE để tối ưu việc khi nào thì cần tiết kiệm pin mà khi nào thì cần hiệu năng cao.
Cơ chế cho thuê bản quyền kiến trúc của ARM khác việc đóng kiến trúc x86 của Intel
Nhưng trong khi ARM với nhiều hãng phát triển (do cơ chế cấp phép bản quyền) dần tốt hơn theo năm tháng thì x86 với chỉ 2 đại diện Intel và AMD (vẫn có VIA nhưng đừng tính làm gì) có vẻ không thay đổi nhiều, mà cụ thể nhất là Intel. Mình có từng phân tích tại sao Intel lại như thế ở một bài viết trước. Có thể gom chung tất cả vào một câu – lãnh đạo như sh!t! Vì cơ bản người đứng đầu không ra gì thì sản phẩm khó mà tiến bộ được. Nhưng đó là tình hình trước khi Pat Gelsinger về cầm trịch Intel (tương tự AMD là con thuyền đang đắm trước khi Lisa Su làm CEO). Có thể thấy mọi thứ thay đổi đã bắt đầu từ Ice Lake (ICL), cho tới Meteor Lake (MTL) và nay là LNL. Dĩ nhiên LNL không phải điểm đến cuối cùng, chúng ta vẫn còn Arrow Lake (ARL) và Panther Lake, nhưng đó là ở thì tương lai.
Sự tiến bộ của x86 (CISC) và ARM (RISC)
Có thể đôi khi bạn thắc mắc – cái gì làm nên sức mạnh của một con chip? Silicon, dĩ nhiên! Mọi con chip mạnh nhất hiện nay đều có số lượng transistor tới hàng chục, thậm chí hàng trăm tỷ. Nhưng đây cũng là một cách nhìn rập khuôn. Silicon về cơ bản giống như số tiền bạn có trong tay, còn làm sao để số tiền đó sinh lời một cách nhanh chóng, an toàn và hiệu quả thì lại tuỳ thuộc nhiều yếu tố. Với chip mà nói, đó là kiến trúc của nó. Hiện tại, có nhiều loại mô hình kiến trúc khác nhau, nhưng phần lớn tồn tại chủ yếu là RISC và CISC.

Khác biệt chính giữa CISC vs. RISC là chiều dài tập lệnh
Có điều RISC vs. CISC là một chủ đề khá dông dài, mình sẽ không nói nhiều ở đây. Chúng ta chỉ tập trung vào các khác biệt chính và những gì dẫn tới kiến trúc LNL của hôm nay. RISC về cơ bản là kiến trúc chip trong đó các tập lệnh có cấu trúc được rút gọn, chiều dài cố định, thường chỉ được thực thi bên trong các ALU/FPU, chúng không truy cập vào dữ liệu ở bộ nhớ ngoài mà chỉ xử lý trên các thanh ghi. RISC có những tập lệnh riêng để thực hiện chức năng lấy dữ liệu ở ngoài vào. Vì thế nó còn được gọi là kiến trúc xuất-nhập (load-store).
CISC ngược lại, sử dụng các tập lệnh cấu trúc phức tạp hơn, thường có cả chức năng truy cập dữ liệu ngoài thanh ghi (ví dụ cache hoặc DRAM). Mục đích là cho phép chúng có thể thực hiện được nhiều phép toán chỉ với 1 tập lệnh (1 tập lệnh RISC thường chỉ làm được 1 việc). Vì vậy, tập lệnh CISC có chiều dài biến động chứ không cố định như RISC. Chi tiết này dẫn tới việc thiết kế ống lệnh cho CISC phức tạp hơn cũng như làm sao để mở rộng số ống lệnh CISC khó hơn RISC nhiều.
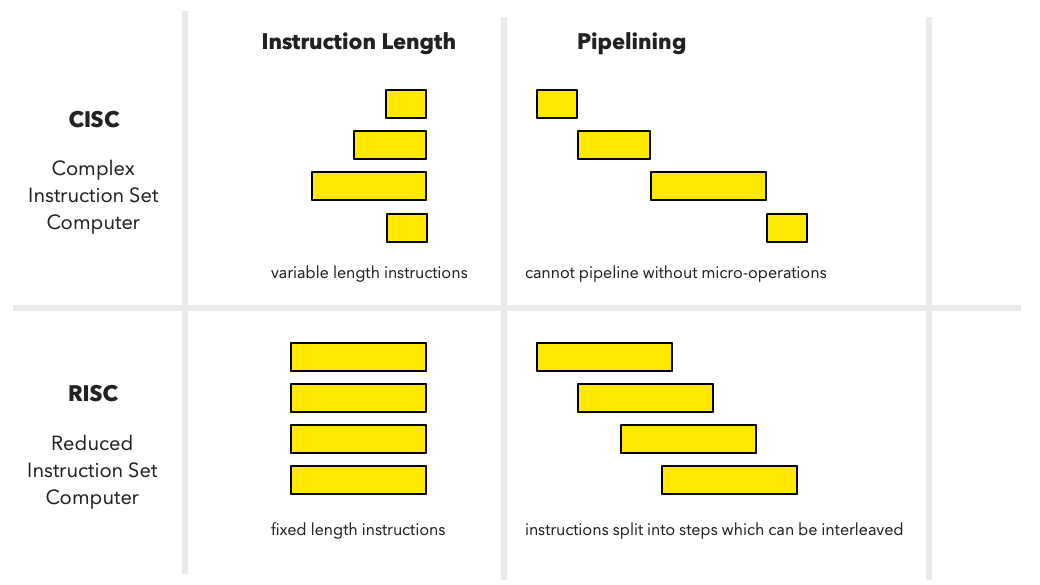
Thiết kế ống lệnh cho CISC phức tạp hơn RISC
Nhưng nói vậy không nghĩa RISC luôn luôn đơn giản. Khi chiều dài các thanh ghi tăng lên thì chiều dài các tập lệnh cũng phải tăng. Đồng thời để có thể giải quyết được nhiều công việc hơn thì RISC cũng cần phải có nhiều tập lệnh hơn trước đó. Ngoài ra vì chiều dài tập lệnh cố định (ở 1 thế hệ kiến trúc), khi chuyển giao sang thế hệ kế tiếp sẽ đòi hỏi việc bổ sung thêm cơ chế chia chiều dài để có thể xử lý được tập lệnh cũ. Bản thân CISC không gặp trục trặc này vì với chiều dài biến động, mọi tập lệnh cũ đều vẫn chạy bình thường trên kiến trúc mới.

RISC cần thực thi nhiều tập lệnh hơn để xử lý 1 công việc
Lẽ tất nhiên con số decoder của từng hãng không nói lên chúng hơn/kém hãng khác. Mà là cơ sở để đánh giá sự thay đổi kiến trúc trong nội bộ hãng đó. Lấy ví dụ kiến trúc K7/K8/K10 của AMD đều là 3-wide decoder, còn Zen 1/2/3/4 cùng 4-wide decoder, nhưng chênh lệch IPC giữa từng kiến trúc là có khác biệt. Còn với Intel, kể từ thế hệ Core đầu tiên cho tới Skylake (Core đời 6-10) là 4-wide, duy nhất đời 11 (Cypress Cove) là 5-wide. 6-wide decoder xuất hiện từ đời 12 và duy trì tới tận hôm nay. Vậy còn LNL?
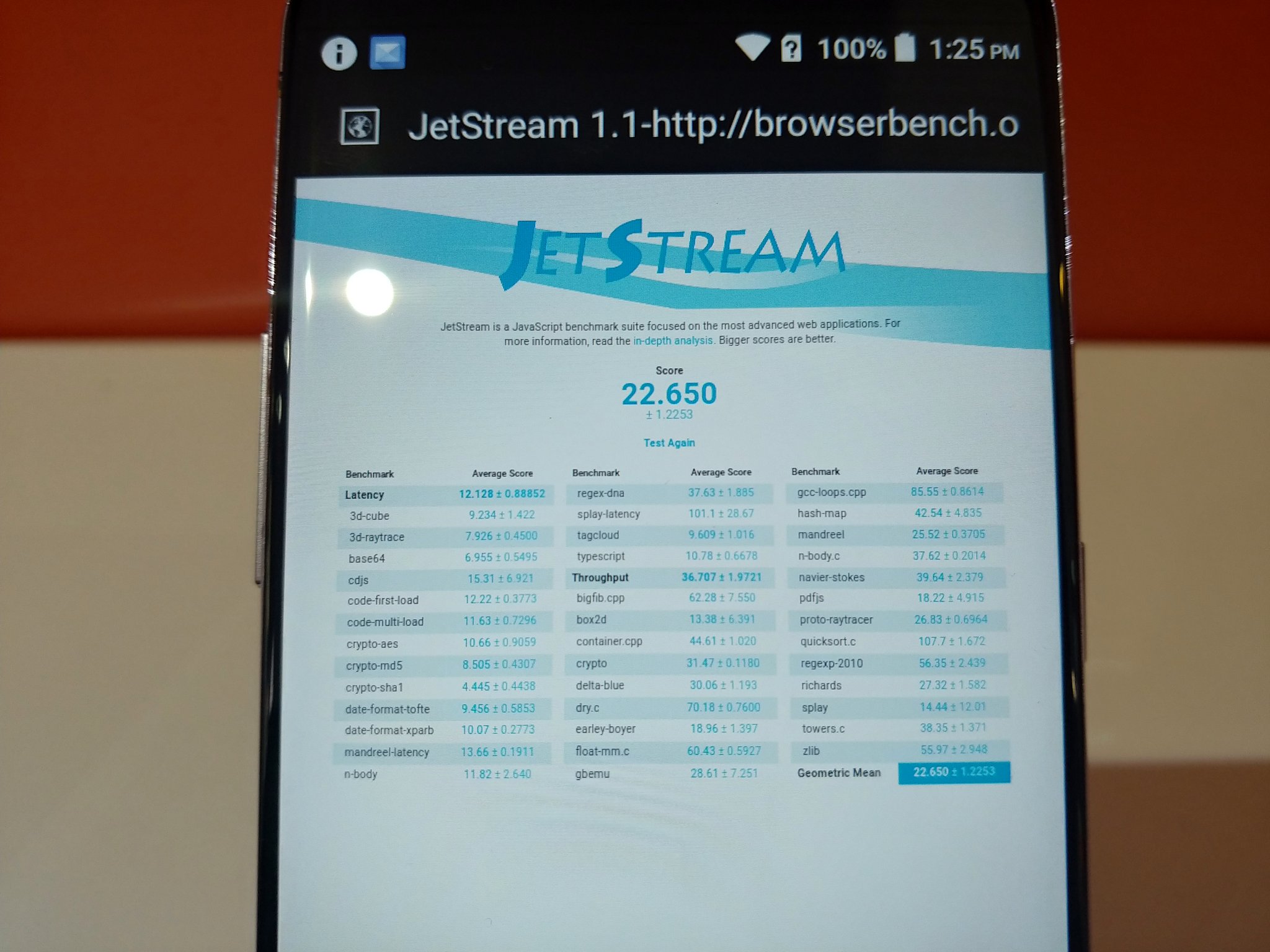
8-wide decoder.
Bức tốc chóng mặt
Một chuyện rõ ràng là kích thước decoder chỉ là một phần trong tổng thể kiến trúc con chip. Nó không phải thang đo tuyệt đối về sức mạnh (IPC), nhưng nó cho thấy “tiềm năng” của con chip này đến mức nào. Một cách ví von dễ hiểu về kiến trúc chip là một doanh nghiệp sản xuất, với một nhân xử lý là một nhà máy. Trong đó, decoder là bộ phận chuyên trách nhận đơn hàng từ ban giám đốc/đối tác gửi xuống. Decoder có kích thước càng lớn thì càng phân tích được rõ đơn hàng hơn cũng như chia được nhiều đầu việc hơn cho các phân xưởng/dây chuyền ở dưới.
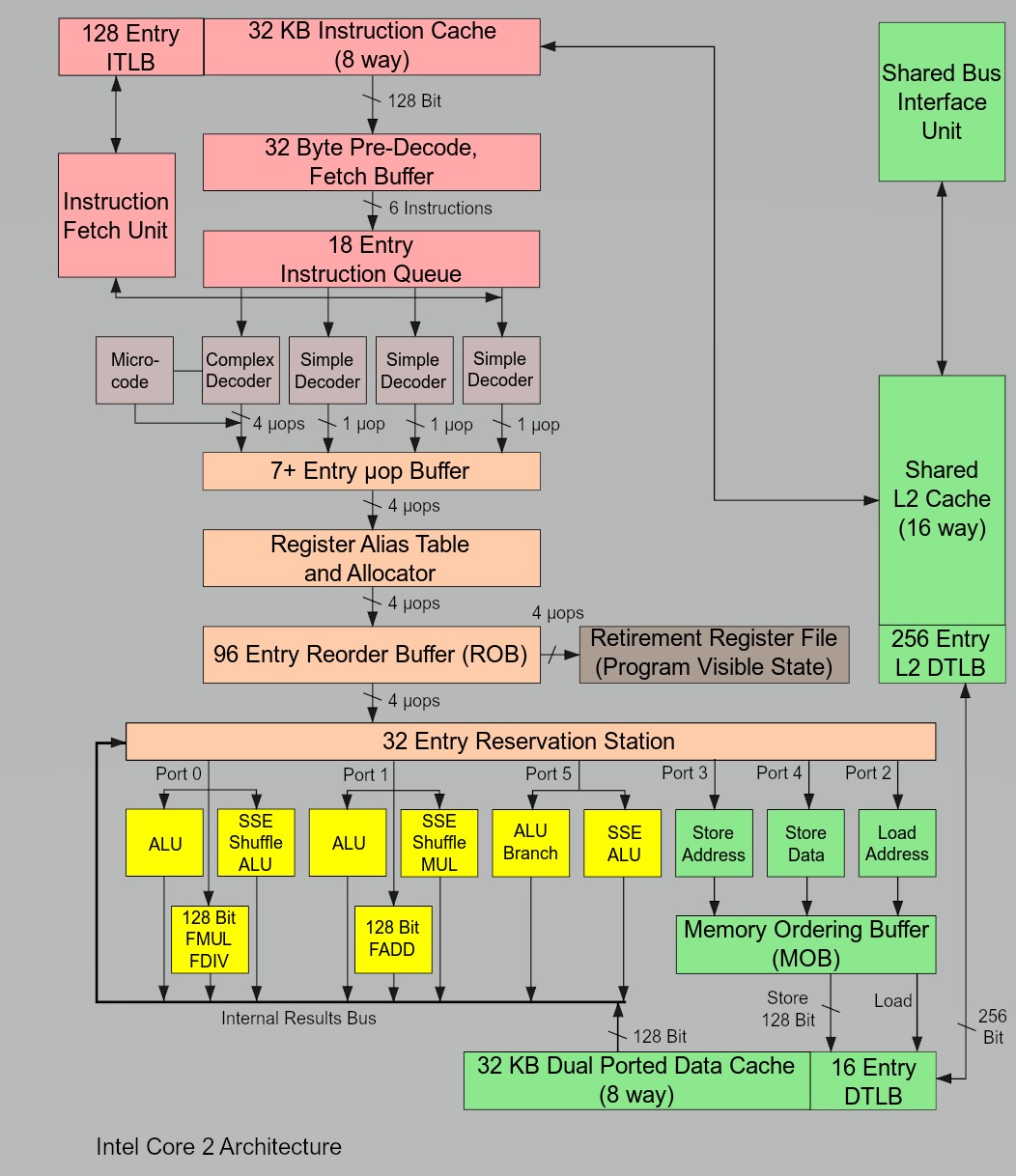
Kiến trúc Intel Core (2006) với 4-wide decoder
Và một logic rất cơ bản là không ai tuyển tới 8 ông trưởng phòng kinh doanh nhưng chỉ tuyển 1 trưởng phòng sản xuất. Cần có sự cân bằng giữa bộ phận chia đầu việc bộ phận xử lý công việc. Trên thực tế bao lâu nay, decoder là bộ phận có số lượng thấp hơn các đơn vị còn lại. Như đã nêu ở trên, AMD duy trì 3-wide decoder trong rất nhiều năm liền rồi mới lên 4-wide. Intel cũng không khác. Nhưng ở lần ra mắt LNL này (chính xác là P-core Lion Cove), thay vì phát triển tiếp 6-wide decoder có trên Redwood Cove (MTL), Intel đã lên thẳng 8-wide! Tại sao phải gấp gáp đến vậy?

Kiến trúc ARM Cortex-X925 (2024) với 10-wide decoder
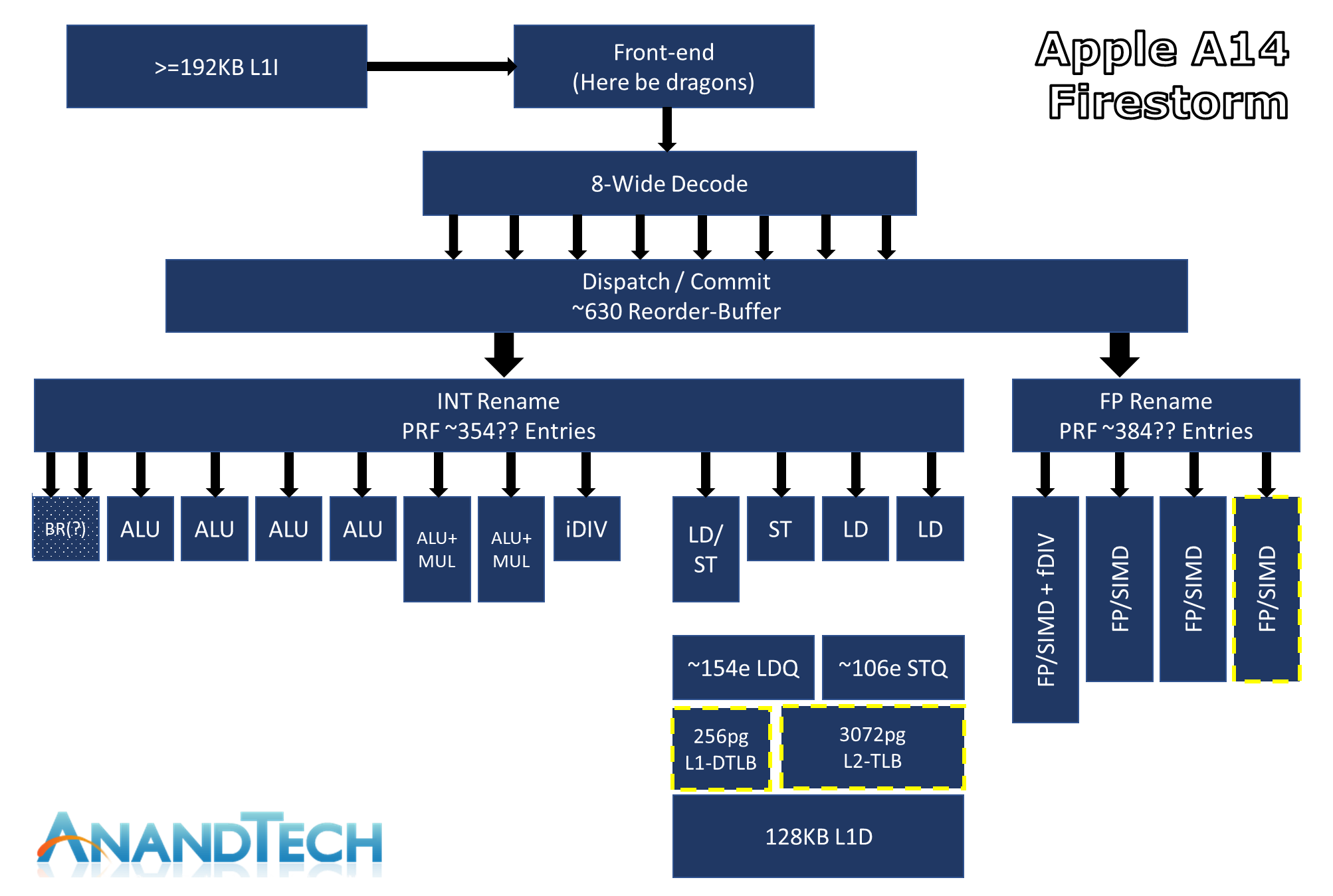
Apple đã áp dụng 8-wide decoder từ 2020 (ảnh Anandtech)
Vì phe ARM đã lên đến 8/10-wide decoder. Cách đây không lâu, ARM vừa công bố nhân Cortex-X925 mới, có thể xem là bản nâng cấp từ Cortex-X4 ra mắt trong 2023, trong đó cả 2 nhân Cortex này đều là 10-wide decoder. Mặc dù decoder của x86 và ARM khác nhau, nhưng quả thực cứ duy trì số lượng decoder thấp thì quả có nhiều khó khăn để so găng với đối thủ. Thế nên Intel chọn cách “nhảy cóc” lên thẳng 8-wide để không bị tụt hậu. Và theo kinh nghiệm của mình, Lion Cove sẽ là nền móng cho kiến trúc x86 của Intel trong nhiều năm tới (vì thay đổi số lượng decoder gần như tương đương với một kiến trúc mới hoàn toàn – một kiến trúc thường tồn tại 4-5 năm).