
Phân tích kiến trúc AMD Zen 5 – Cải tiến lớn nhất kể từ Zen ‘đời đầu’ (phần 2)
Front-end
Do đã nói nhiều decoder ở phần 1 nên mình không nhắc lại nữa. Ngoài decoder ra thì các thành phần như Bộ đệm Tập lệnh (L1I Cache), Bộ tiên đoán rẽ nhánh (BPU), Bộ đệm Vi lệnh (Op Cache) cũng có vai trò rất quan trọng. Đáng chú ý là các thành phần này dường như đều được x2 để đáp ứng cho phù hợp bộ decoder đôi đã nói trước đó.
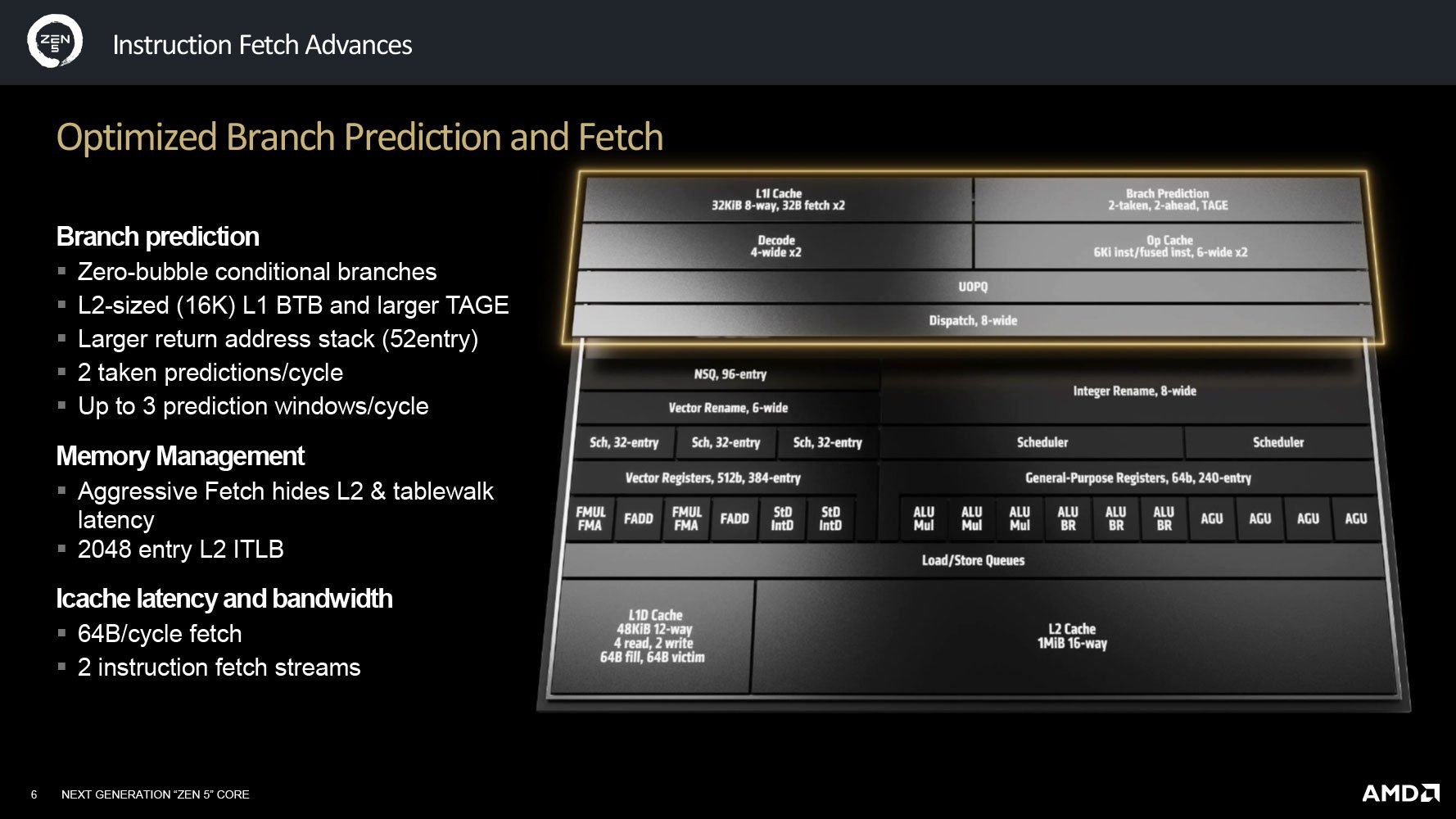
Front-end Zen 5 có nhiều bộ phận x2 theo decoder
Trong cấu tạo vi xử lý, BPU có vai trò gần giống CEO của công ty. Nó tiên đoán trước những nhánh công việc tiếp theo cần làm để từ đó, lên sẵn danh sách các tập lệnh cần thiết cho chu kỳ tính toán sau xử lý. Dĩ nhiên nếu BPU tiên đoán sai thì những tập lệnh mà nó gửi xuống sẽ thành vô nghĩa và quá trình tính toán trở thành công cốc, gây thiệt hại cho hiệu quả công việc. Trên Zen 5, bộ BPU mới cho phép tiên đoán có điều kiện theo cơ chế zero-buble. Nó được nâng cấp bộ L1 BTB lớn hơn đáng kể so với Zen 4 – từ 1.5K lên tới 16K! Bộ stack địa chỉ trả về cũng được mở rộng hơn (32 vs. 52 entry). Kết quả là BPU Zen 5 cho phép đoán trước tới 3 cửa sổ/chu kỳ (BPU Zen 4 chỉ có 2).
Do có 2 decoder nên nhân Zen 5 cũng có tới 2 Op Cache. Chi tiết thú vị là tổng độ dài Op Cache Zen 5 cũng tới 12-wide (2x 6-wide), ngang bằng Lion Cove của Intel. Như vậy sơ sơ thì bên tám lạng, bên nửa cân. Vai trò của Op Cache chủ yếu chứa các tập lệnh được dùng lại nhiều lần, giúp giảm tải công việc cho decoder, giúp quá trình gửi lệnh (fetch) xuống dưới diễn ra liên tục, ít bị gián đoạn giữa chừng. Op Cache Zen 5 có dung lượng tới 6K vi lệnh, cho băng thông tối đa 12 vi lệnh/chu kỳ (tăng từ 9 so với Zen 4). Năng lực liên kết bộ nhớ Op Cache Zen 5 cũng cao hơn thế hệ trước, từ 12-way lên 16-way.
L1I Cache là thành phần dường như không đổi so với trước, dung lượng vẫn 32 KB, liên kết nhớ 8-way, hiệu suất 2x 32 bit/chu kỳ (có vẻ tương ứng với 2 decoder phía dưới).
Về tổng quan, front-end Zen 5 cho phép gửi đi (Dispatch) 8 vi lệnh/chu kỳ, hoặc cho nhân số nguyên (INT) hoặc số thực (FPU), tương đương với Front-end Lion Cove.
Xử lý số nguyên
Execution có lẽ là phần mà AMD bắt đầu khác biệt so với Intel. Nếu như Intel có thêm một lớp OoO để phân loại chia tách các vi lệnh INT/FPU thì AMD sự phân loại đi theo chu kỳ (hoặc INT hoặc FPU). Sau đấy tuỳ là INT hay FPU mà mỗi bên sẽ có Bộ chia lịch (Scheduler) hay Sửa tên (Rename) riêng. Ở đây, phần Rename INT cũng có bề rộng 8-wide tương ứng với Dispatch ở trên.

INT Zen 5 có 6 ALU và 4 AGU
Tuy vậy, INT Zen 5 “chỉ có” 6 ALU và 4 AGU, tăng lên từ 4 ALU và 3 AGU trên Zen 4. Nhưng Decoder Zen 4 là 4-wide, nên Execution của Zen 4 là “dư” so với Front-end. Nên có thể thấy INT Zen 5 có phần “hụt hơi” so với Front-end. Bù lại thì đặc tính chia vi lệnh theo chu kỳ nên khi INT đang “bận” thì Front-end có thể gửi việc cho FPU và ngược lại. Vả lại trong thiết kế chip, những thế hệ kiến trúc đầu tiên sẽ không bao giờ hoàn hảo mọi thứ, sẽ luôn có vấn đề để khắc phục ở các phiên bản sau. Lý do là vì “quỹ” transistor có hạn, các kỹ sư buộc phải đánh đổi không cái này thì cái khác. Dù sao bên Lion Cove cũng chỉ có 6 ALU INT nên Zen 5 cũng xem là “ngang kèo”.
Dĩ nhiên, khi thay đổi số lượng ALU/AGU thì các thành phần hỗ trợ chúng cũng sẽ thay đổi theo. Scheduler INT ALU nay được tách riêng với Scheduler INT AGU (trên Zen 4 gộp chung). Scheduler ALU Zen 5 hỗ trợ tới 88 entry, AGU là 56 entry (tổng 144 entry, so với tổng Zen 4 là 4x 24 = 96 entry). Thanh ghi (register file) INT Zen 5 tăng lên 240/192 entry (Zen 4 là 224/126 entry). Bộ đệm ROB INT Zen 5 tăng tới 448 entry (Zen 4 là 320 entry).
Xử lý số thực
Trong khi số nguyên là những thứ chúng ta thường dùng hàng ngày, số thực lại là những công việc có tính “nặng nhọc”, ví như render, decode/encode video, 3D gaming, tính toán AI… Nhưng vì thế FPU cũng là thành phần tương đối ngốn nhiều transistor, có lẽ chỉ sau Cache (phần lớn transistor vi xử lý ngày nay là dùng cho bộ nhớ). Trên Zen 5, FPU được đầu tư tương đối kỹ và có lẽ trong tầm nhìn của Lisa Su, CPU vẫn là nòng cốt để “combat” với Intel lẫn NVIDIA trên mặt trận server/HPC (siêu máy tính).
Chi tiết thú vị và cũng gần như quan trọng nhất trên FPU Zen 5 chính là năng lực xử lý AVX-512. Đây là điểm rất khôi hài với mình =)))) Vì AVX-512 là thứ mà Intel đã dồn bao nhiêu tâm huyết để đầu tư, cũng như xây dựng hệ sinh thái cho nó (bắt đầu từ 2013, từ những con chip Knight Landing chỉ dành cho server). Có rất nhiều chuyện “chìm nổi” giữa Intel và AVX-512. Cha đẻ Linux từng “nguyền rủa” AVX-512 nên “chết đau đớn” (I hope AVX-512 dies a painful death), lý do vì sự phân mảnh mà Intel tạo ra chỉ trong nội bộ các tập lệnh con cho AVX-512 khiến cho việc tích hợp chúng gặp nhiều khó khăn. Đặc biệt việc xử lý AVX-512 rất ngốn điện và toả nhiều nhiệt, phần lớn chip Intel phải giảm xung khi kích hoạt chế độ AVX-512 để không bị quá nhiệt.

FPU Zen 5 với năng lực tính toán AVX-512
Đây cũng là lý do mà những thế hệ chip Intel dành cho người dùng phổ thông (Core) gần đây, các tập lệnh AVX-512 đã bị bỏ (chúng vẫn có mặt trên dòng Xeon cho server). Song Lisa Su dường như có quan điểm khác…
Zen 5 và 5c hỗ trợ đầy đủ AVX-512, ngay cả phiên bản chip phổ thông như Ryzen cũng có AVX-512. Lý do? Chính là AI. Trong những năm tháng “đau thương” của mình, Intel đã phát triển AVX-512 theo hướng tính toán AI thông qua các tập lệnh VNNI 512-bit. Tính tới hiện tại, hệ sinh thái AI dựa trên AVX-512 tương đối hoàn thiện nên nếu bỏ qua AVX-512 thì quả là sai sót cho AMD. Vậy nên… đúng người đúng thời điểm chính là đây.
Dĩ nhiên, hỗ trợ 512-bit không phải chuyện đơn giản. Các thế hệ FPU Zen trước đây chỉ hỗ trợ các vector 256-bit. Nếu muốn xử lý 512-bit, FPU Zen 4 phải “chẻ đôi” thành 2 đoạn, xử lý trong 2 chu kỳ. Với Zen 5 thì tất cả có thể làm trong 1 chu kỳ, trên lý thuyết là nhanh x2 thế hệ trước. Mỗi chu kỳ FPU Zen 5 thực hiện được 2 lệnh nạp (load) và 1 lệnh chứa (store) 512b. Một phép toán FADD tốn 2 chu kỳ.
FPU Zen 5 được tăng lên 4 ống lệnh, nghĩa là ngang cơ FPU Lion Cove (tăng lên từ 3 ống lệnh của Zen 4). Kích thước register file FPU Zen 5 tăng lên gấp đôi (từ 192 lên 384 entry). Scheduler FPU Zen 5 tăng lên tới 3 đơn vị, mỗi đơn vị hỗ trợ 38 entry (Zen 4 có 2 Scheduler, mỗi cái 32 entry).
Back-end
Dĩ nhiên khi một nhà máy mở rộng sản xuất, tăng thêm số dây chuyền làm việc… thì kho chứa hàng cũng phải mở rộng hơn. Phần thay đổi nhiều nhất ở Back-end Zen 5 là L1 Data Cache, vì đây là nơi nhận “hàng” từ cả INT lẫn FPU “làm ra”. Tuy dung lượng L1D Zen 5 chỉ tăng “nhẹ” lên 48 KB so với 32 KB của Zen 4, nhưng số liên kết nhớ (associativity) của nó đã tăng từ 8-way lên 12-way. Số liên kết nói lên khả năng “giao hàng” của bộ nhớ đó với các bộ phận khác. Một cách dễ hình dung là càng có nhiều cao tốc liên kết 2 thành phố/bến cảng thì hàng hoá lưu thông càng dễ dàng. AMD cho biết L1D Zen 5 có độ trễ 4 chu kỳ, rất là ấn tượng vì L0 của Lion Cove cũng có độ trễ tương đương và cùng mức dung lượng. Xưa nay, AMD thường không bằng Intel ở tốc độ cache.
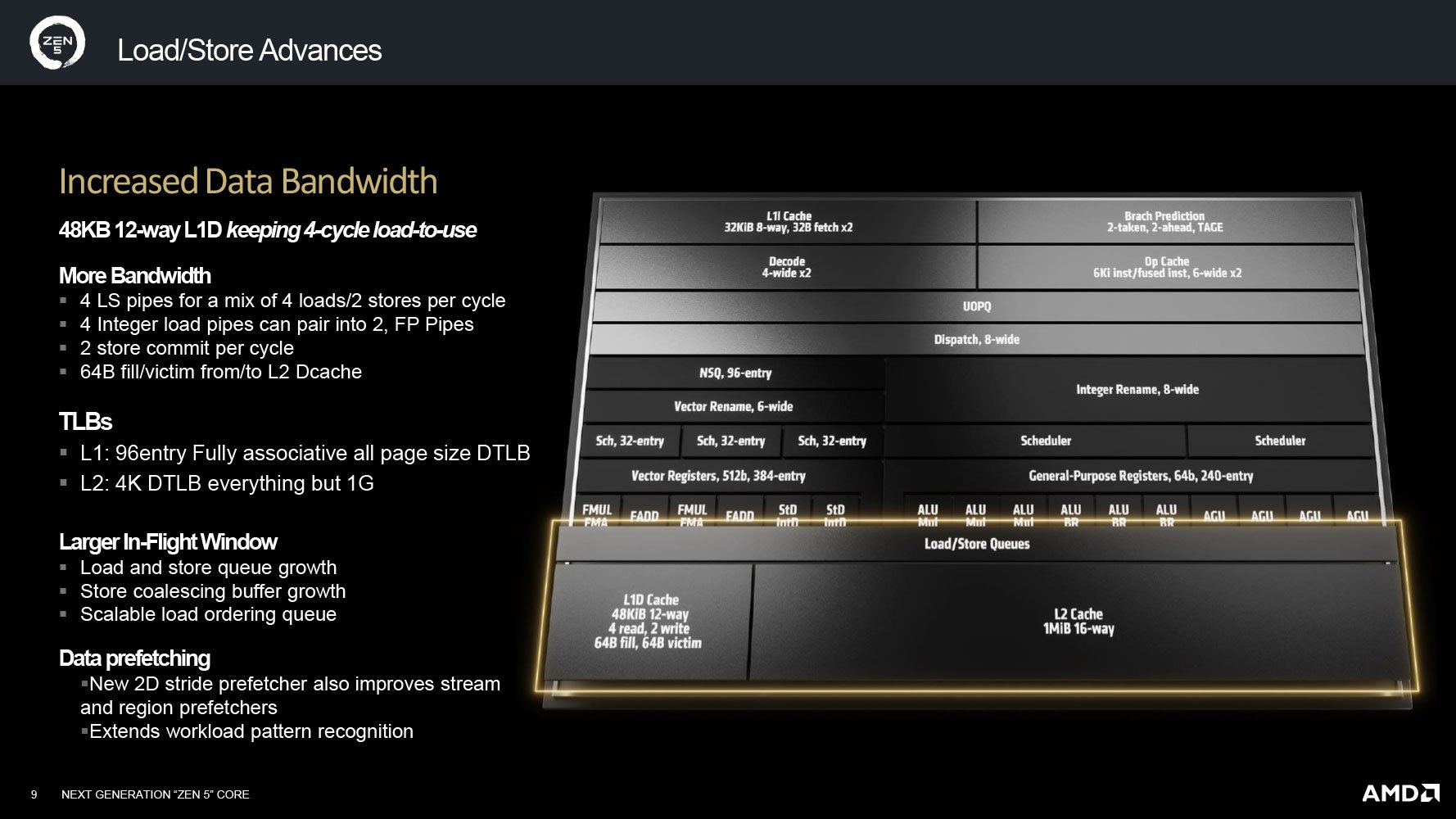
L1, L2 Cache được nâng cấp mạnh khả năng liên kết nhớ
Năng lực nhập/chứa dữ liệu Zen 5 cũng cao hơn Zen 4, từ 3/1 lên 4/2 ống lệnh. Bộ TLB hỗ trợ L1/L2 cũng tăng từ 72/3072 (Zen 4) lên 96/4096 entry (Zen 5). Đáng chú ý nếu toán tử là 512b thì năng lực nhập/chứa giảm còn 2/1 lệnh/chu kỳ. Ngoài ra, 4 ống lệnh nạp INT có thể được chập đôi lại thành 2 ống FP khi cần thiết.
Sang L2 Cache (chứa cả dữ liệu và tập lệnh), dung lượng vẫn giữ nguyên ở mức 1 MB, nhưng độ liên kết tăng lên 16-way (gấp đôi 8-way trên Zen 4), cho phép nó đạt băng thông 64b/chu kỳ. Dữ liệu từ L1I hoặc L1D đều có thể copy sang L2 theo hình thức victim với tốc độ 64b/chu kỳ.
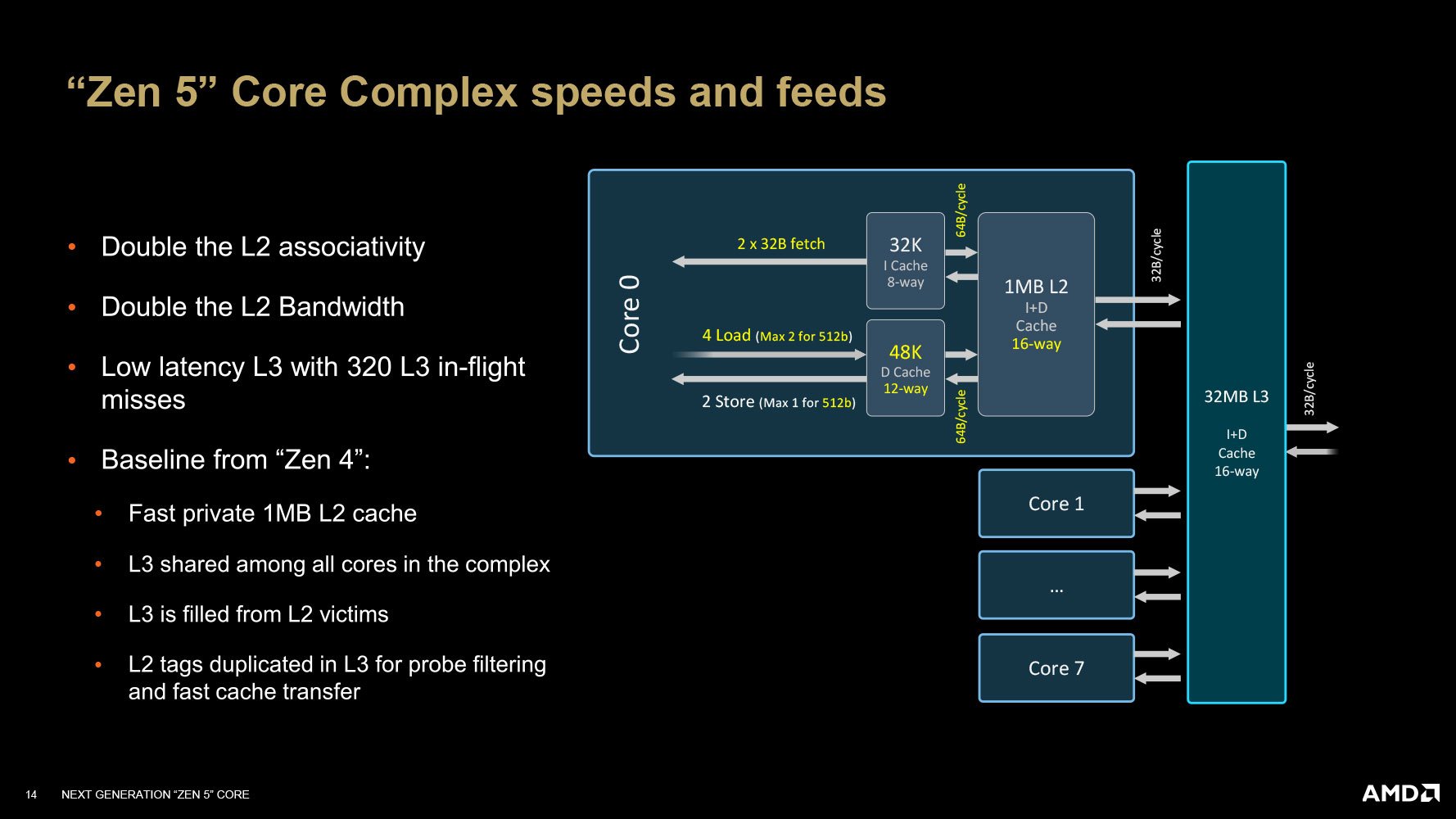
Mô hình trao đổi dữ liệu giữa L1I, L1D, L2 và L3 Cache của Zen 5
Tuy vậy, khi copy từ L2 Cache sang L3 Cache (dùng chung giữa 8 nhân Zen 5) thì băng thông này giảm còn 32b/chu kỳ. Và từ L3 Cache sang các nơi khác cũng 32b/chu kỳ. L3 Cache có dung lượng 32 MB (trung bình 4 MB/nhân), liên kết 16-way.
Và tới đây, chúng ta có 1 die CCD Zen 5 cơ bản, gồm 8 nhân Zen 5, L3 Cache 32 MB, SMU quản lý toàn bộ khối CCD cùng bộ liên kết Infinity Fabric để liên kết với các chiplet khác (I/O die, CCD, GDC). Trừ trường hợp monolithic như Strix Point, các sản phẩm Ryzen/EPYC khác của AMD cũng sẽ dựa trên việc ghép LEGO die CCD này với các die CCD và I/O khác. Trong đó, nhân Zen 5/5c là “linh hồn” của tất cả.
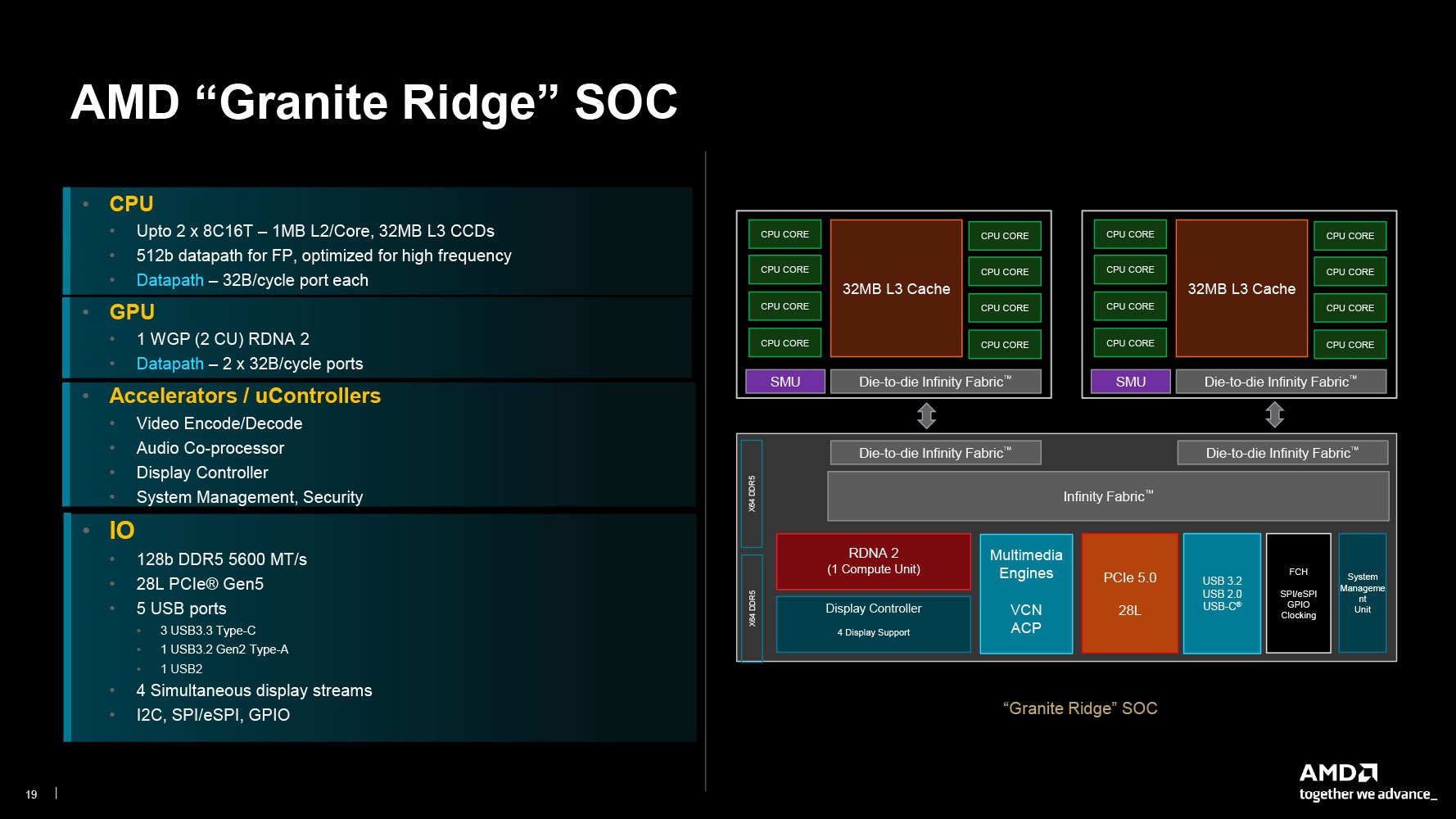
Cấu tạo cơ bản một chip Ryzen Zen 5 dành cho desktop
Những benchmark sơ bộ và lời kết
Như vậy là chúng ta đã tìm hiểu cơ bản kiến trúc Zen 5 của AMD. Đây là một trong những thay đổi lớn nhất của AMD kể từ Zen 1 cũng như là từ Bulldozer. Trước các biến động của thị trường công nghệ, Zen 5 không chỉ phải đối đầu với riêng Lion Cove của Intel mà còn cả từ Snapdragon của Qualcomm (và có thể cả MediaTek, Samsung, Huawei…). Tới nay, các benchmark sơ bộ của Zen 5 lần lượt đã có, gồm cả Windows và Linux. (Lưu ý rằng những kết quả này được thực hiện thử nghiệm lúc chưa có bản cập nhật mới của Windows 11)
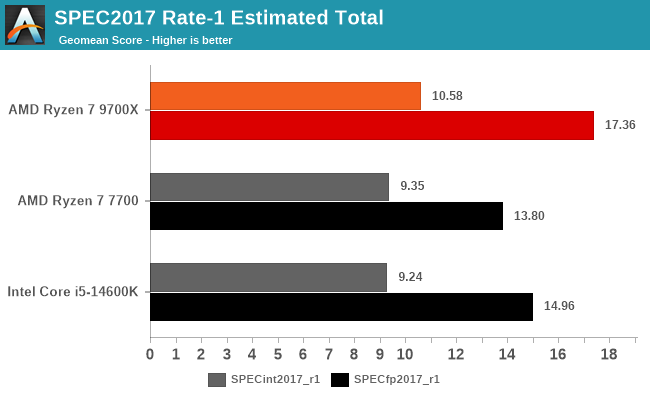
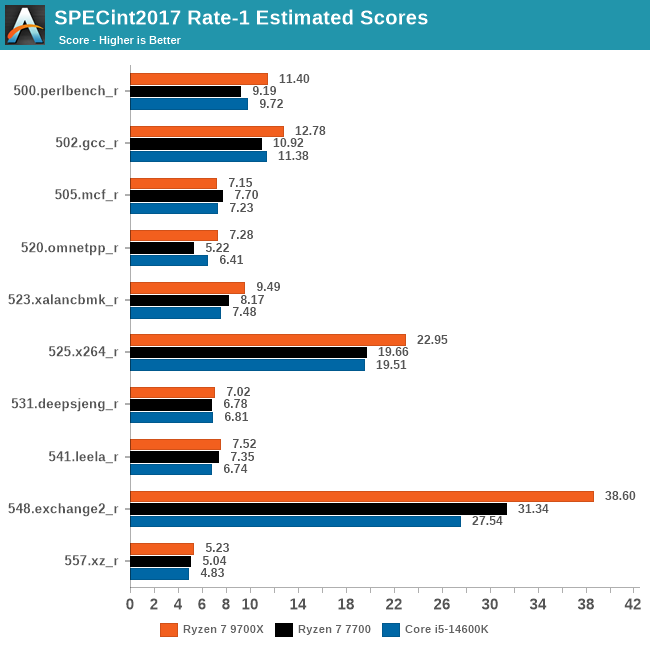
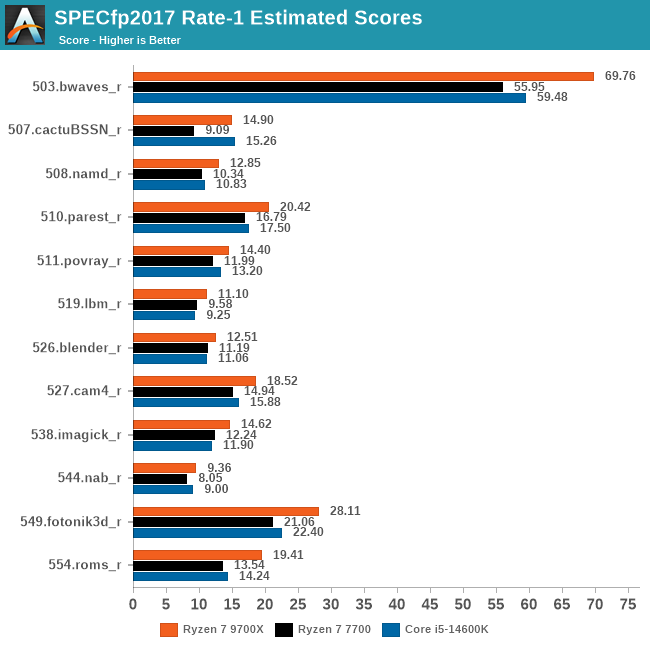
So sánh hiệu năng đơn luồng của Zen 4, Zen 5 và Raptor Lake
Trên thực tế AMD có công bố IPC của Zen 5 cao hơn Zen 4 16%. Nếu thoạt nhìn chênh lệch decoder thì con số này khá… tệ (4-wide và 8-wide). Tuy nhiên bạn cần chú ý Zen 4 là ở “cuối đường” của 4-wide, hiệu năng của nó cao hơn Zen 1 rất nhiều. Còn Zen 5 mới là khởi điểm của 8-wide, thế nên khoảng cách Zen 4 và Zen 5 là có thể hiểu được. Zen 6 trở về sau chắc chắn sẽ có sự cải thiện IPC cao hơn thế hệ này, nhưng sẽ là câu chuyện ở thì trong lai.
Ngoài ra khi so sánh với Intel, nhất là hiệu năng đơn luồng, các con chip nền tảng Raptor Lake (thế hệ 13/14) có cấu trúc 6-wide decoder cho thấy chúng đã yếu hơn Zen 5. Dĩ nhiên khi benchmark đa luồng có sự kết hợp của cả P-core và E-core thì mọi thứ trở nên khó phân biệt hơn.


Tổng quan sức mạnh Zen 5 trên Windows
Có một tình huống hết sức đáng chú ý với mình đó là Linux. Dường như Zen 5 vận hành hiệu quả hơn trên hệ điều hành này. Theo ghi nhận của Phoronix, 2 con chip 6 nhân (9600X) và 8 nhân (9700X) Zen 5 của AMD dường như chỉ kém hơn 2 con chip desktop đắt tiền nhất hiện nay bên Intel gồm 13900K và 14900K (24 nhân với 8 nhân P)! Thậm chí chúng còn “đe doạ” cả “gà nhà” Ryzen Zen 4! Một số trang cho hay do quy định TDP 65W nên khi benchmark, các chip Ryzen Zen 5 đã bị “trói chân trói tay”, chúng không được tự do turbo boost nhất là lúc chạy đa luồng. Nhưng khi được “tháo gông” PBO thì mọi thứ rất khác, nói kiểu nôm của racer là được “mở” ECU…
Tất nhiên khi turbo, con chip sẽ ngốn điện hơn. Dù vậy do được sản xuất trên tiến trình TSMC N4P, về cơ bản Ryzen Zen 5 vẫn đỡ ngốn điện hơn các đại diện Core 13/14 nhà Intel. Thắc mắc của mình lúc này là Arrow Lake được gia công ở TSMC sẽ ngốn điện đến mức nào? Xem chừng cuộc đấu PC 2024 vẫn còn nhiều điều thú vị phía trước.
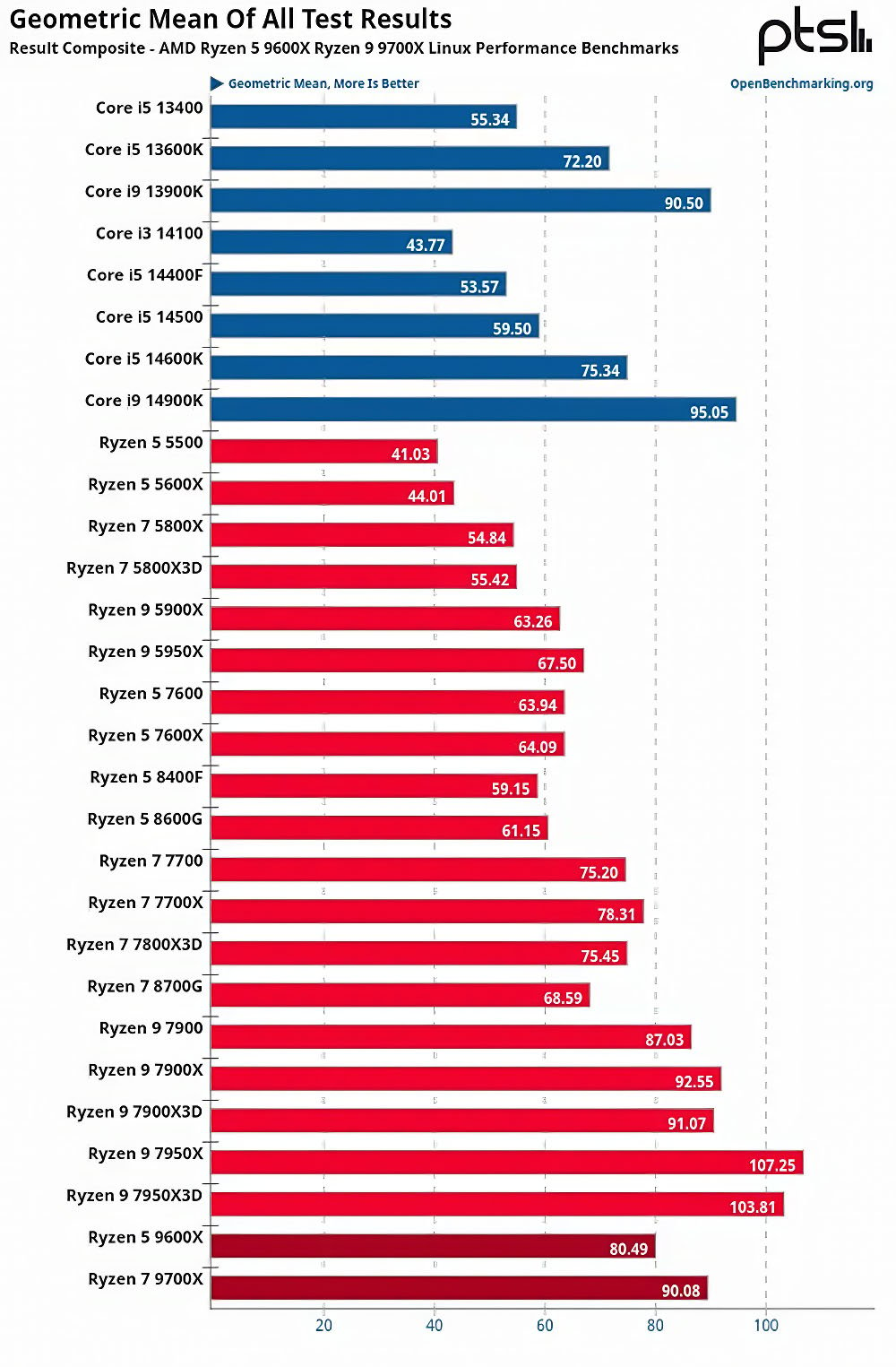
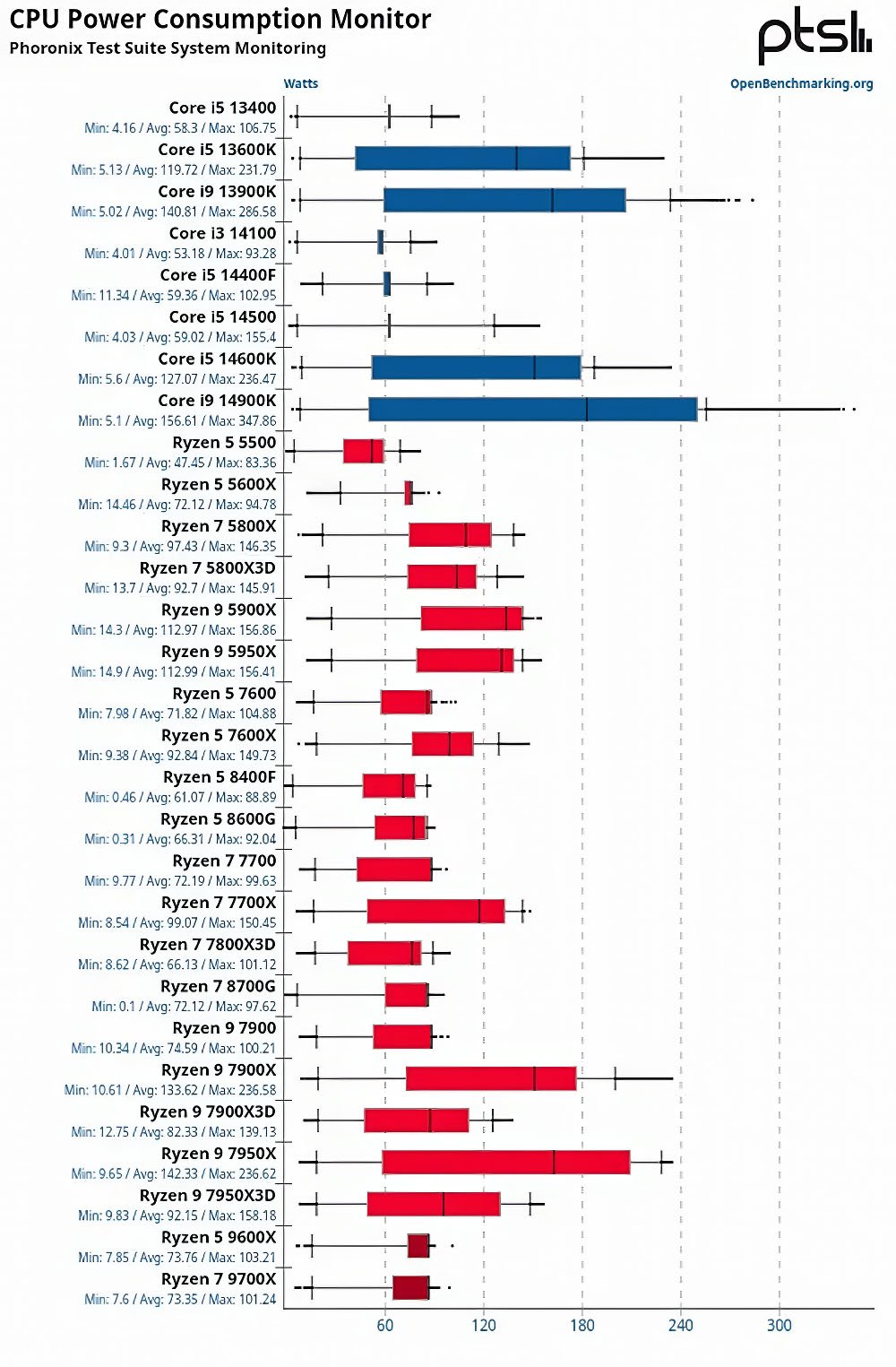
Tổng quan sức mạnh Zen 5 trên Linux
Tổng kết chung, Zen 5 cho thấy AMD đang có những bước đi đúng đắn. Một kiến trúc mạnh mẽ hơn, khai thác tốt hơn những nơi cần khai thác (AVX-512, AI), và vẫn còn nhiều dư địa để cải tiến về sau. Đây chắc chắn là một bước đà tốt cho những sản phẩm về sau của công ty này.