
Chip xử lý Nvidia Blackwell gặp lỗi thiết kế, lỗi do cả Nvidia lẫn TSMC, hoãn ra mắt vài tháng
Sự cố mang tính kỹ thuật này cũng đã khiến Nvidia phải thiết kế lại toàn bộ hệ thống chip xử lý kiến trúc Blackwell, dẫn tới những hệ lụy không đáng có với cả những đối tác trong chuỗi cung ứng và phân phối.
Con chip xử lý tối tân mà Nvidia tạo ra phục vụ cơn sốt AI, thuộc thế hệ kiến trúc chip Blackwell có tên GB200. Với con chip này, Nvidia lựa chọn ứng dụng những tiến bộ kỹ thuật gia công bán dẫn mới nhất mà TSMC tạo ra. Với con chip này, Nvidia trang bị được một hệ thống 72 chip GB200, mang tên DGX GB200 NVL72. Máy chủ này ngốn tới khoảng 125 kW điện, cao hơn rất nhiều so với con số trung bình từ 15 đến 20 kW điện cho mỗi rack máy chủ trong data center hiện nay.

Với DGX GB200 NVL72, Nvidia tạo ra được mật độ hiệu năng xử lý và tiêu thụ điện năng chưa từng có. Nhưng khi xét đến mức độ phức tạp của toàn bộ hệ thống hay chính bản thân từng con chip xử lý GB200 đơn lẻ trong máy chủ DGX, rất nhiều vấn đề đã nảy sinh. Từ việc cấp điện, nhiệt năng tỏa ra, hệ thống làm mát bằng chất lỏng, rồi ống dẫn nước làm mát bị rò rỉ do thiết kế tháo lắp nhanh phục vụ cho sự tiện lợi của nhân sự bảo trì hệ thống, và cả những rắc rối đến từ thiết kế bo mạch quá phức tạp…
Tuy nhiên, vấn đề mấu chốt ảnh hưởng tới tốc độ sản xuất và cung cấp đơn hàng chip GB200 Blackwell đến từ chính thiết kế bán dẫn của Nvidia, kết hợp với những rắc rối trong quá trình đóng gói die silicon để tạo ra con chip kích thước cực lớn, dựa trên kỹ thuật CoWoS-L của TSMC.
Tóm tắt lại quy trình CoWoS (Chip-on-Wafer-on-Substrate) của TSMC. Kỹ thuật này ứng dụng một lớp interposer RDL với cầu nối silicon interconnect (LSI) cùng những die silicon làm cầu nối trong lớp interposer, để kết nối tất cả các die silicon xử lý logic, rồi bộ nhớ HBM xung quanh con chip xử lý lại với nhau. Bên cạnh CoWoS-L, quy trình đóng gói die silicon bán dẫn được ứng dụng để sản xuất ra GB200 cho Nvidia, TSMC còn có CoWoS-S, với bức độ phức tạp và diện tích lớp interposer trên nền substrate silicon nhỏ hơn nhiều.
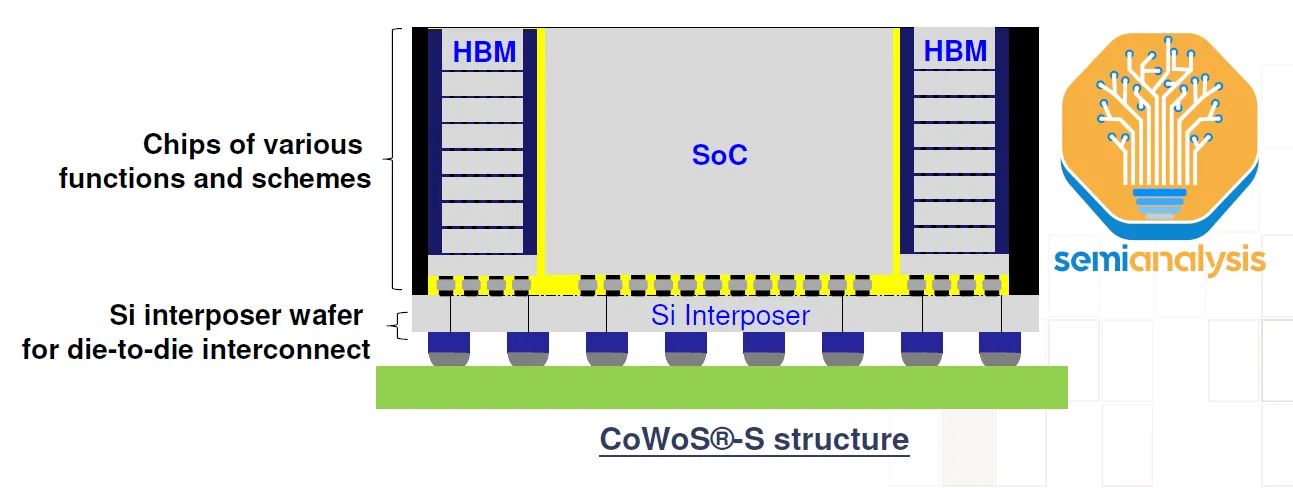
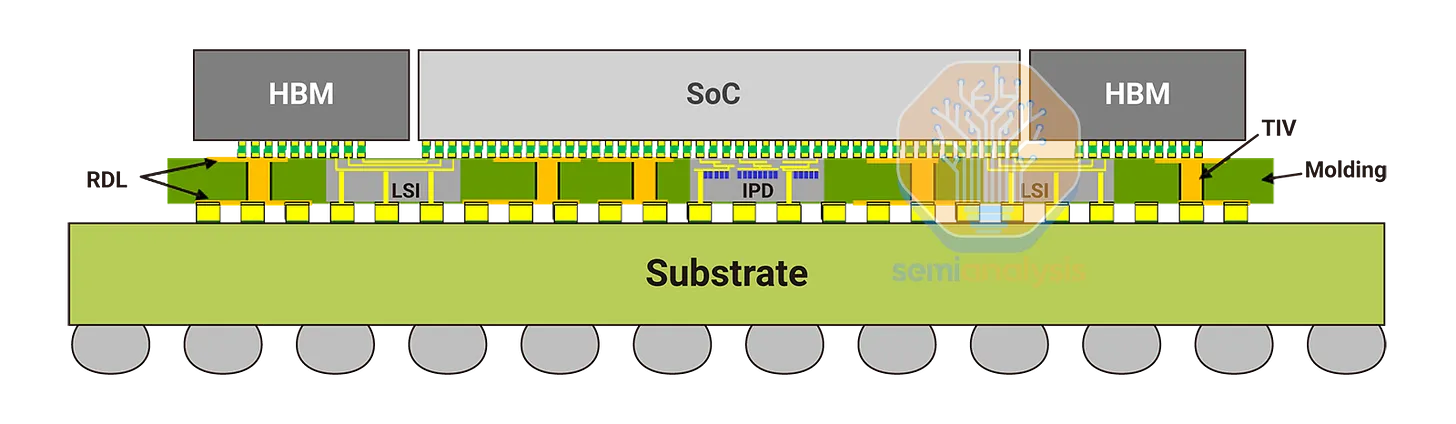
CoWoS-L chính là bản nâng cấp, mở rộng kích thước chip xử lý thế hệ mới của TSMC, dựa trên thiết kế CoWoS-S. Lý do cần có CoWoS-L đến từ chính những yêu cầu về hiệu năng của những thế hệ chip tăng tốc xử lý AI mới, với yêu cầu nhồi nhét càng lúc càng nhiều nhân xử lý logic, bộ nhớ và chip xử lý tín hiệu I/O.
Hiện tại, CoWoS-S đang được TSMC ứng dụng để gia công những con chip Instinct MI300 của AMD. Nhờ kỹ thuật đóng gói chip xử lý này, con chip thành phẩm hàn lên PCB để tạo ra sản phẩm thương mại có kích thước lên tới 3.5 lần kích thước gia công tối đa mà những cỗ máy quang khắc EUV hiện tại có thể làm được thông qua những thấu kính điều hướng ánh sáng dùng trong quá trình quang khắc. Và con số tỷ lệ kích thước này cơ bản cũng là giới hạn của CoWoS-S hiện tại.
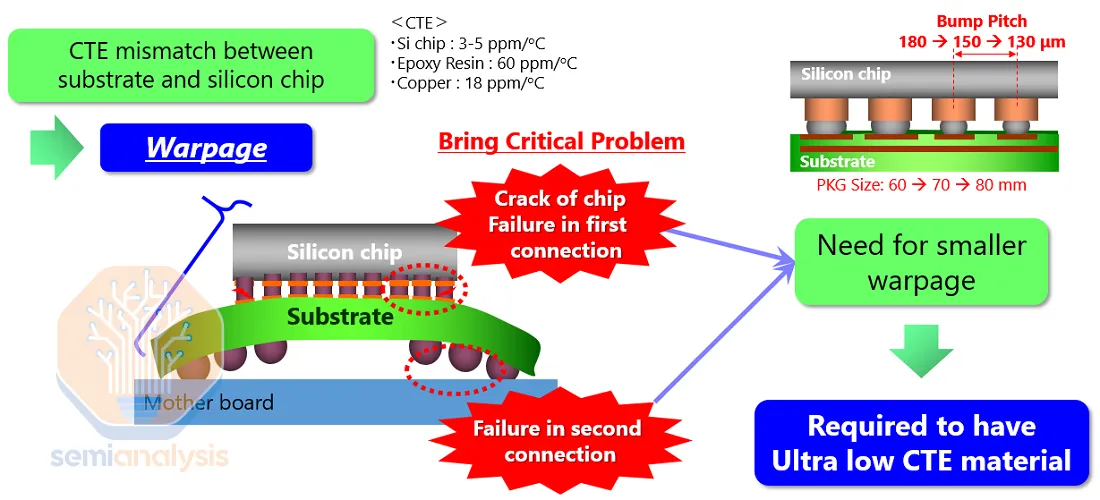
Có nhiều lý do khiến TSMC không thể làm ra một con chip kích thước khổng lồ ghép nhiều die silicon lại với nhau, vượt quá tỷ lệ kích thước 3.5 lần so với một die silicon dạng monolithic mà máy có thể quang khắc. Nhưng lý do mấu chốt, silicon là thứ chất liệu rất giòn. Làm ra những die bán dẫn kích thước bằng móng tay thì không sao, nhưng khi tạo ra những lớp interposer vừa mỏng vừa có diện tích lớn, rắc rối trong khâu gia công sẽ nảy sinh. Rồi chi phí cũng sẽ tăng khi lớp interposer làm nền cho cả con chip đóng gói dựa trên kỹ thuật CoWoS cũng sẽ tăng theo, vì phải ghép các die bán dẫn lại với nhau.
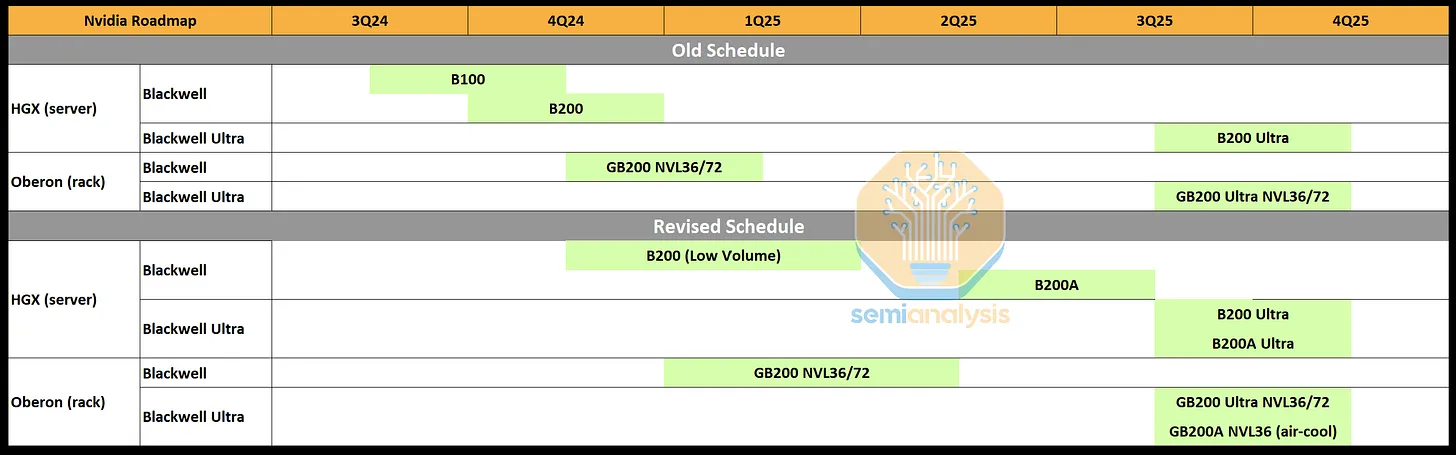
Vậy là TSMC thiết kế ra kỹ thuật đóng gói die silicon CoWoS-L, coi đó là tương lai của ngành công nghiệp bán dẫn. Vấn đề lại nằm ở chỗ, Nvidia và TSMC đang hơi kỳ vọng quá mức, cũng như triển khai lịch trình gia công GB200 dựa trên CoWoS-L có phần vội vàng. Hệ quả tiêu cực tất yếu xảy ra.
Thứ nhất, cầu nối interposer có thể hình thành những khu vực mấp mô trên bề mặt, từ đó tạo ra chênh lệch hệ số nở nhiệt giữa những die silicon, cầu nối và substrate. Vậy là chip sẽ bị cong.
Áp dụng vào trường hợp của một con chip hiệu năng cao trang bị trong máy chủ, điều đó không được phép xảy ra, nhất là với một sản phẩm sở hữu cầu nối kết nối hai die chip xử lý logic cùng băng thông lên tới 10TB/s giữa hai con chip. Rồi bản thân thiết kế cầu nối kết nối dữ liệu giữa hai die logic trong GB200 cũng được cho là gặp vấn đề. Nvidia đang phải thiết kế lại cầu nối này. Một tin đồn khác, là Nvidia đang phải thiết kế lại lớp kim loại kết nối các die silicon lại với nhau.
Vì lý do đó, GB200 sẽ chậm giao hàng vài tháng.

Hiện tại TSMC đang vừa xây dựng fab mới mang tên AP6, chỉ dùng để đóng gói chip CoWoS-L, cùng lúc nâng cấp fab AP3 để chuyển đổi quy trình CoWoS-S sang CoWoS-L. Chính vì lẽ đó, tốc độ gia công chip dựa trên kỹ thuật CoWoS-L sẽ còn chậm hơn so với dự kiến.
Kết hợp cả hai yếu tố, vấn đề của quá trình thiết kế con chip của Nvidia với sản lượng gia công chip CoWoS-L của TSMC, có khả năng TSMC sẽ không kịp sản xuất và cung ứng chip GB200 theo yêu cầu đơn hàng mà Nvidia đặt ra.
Hệ quả là Nvidia sẽ tập trung sản xuất ra những hệ thống GB NVL 36×2 và NVL72. Những máy chủ thiết kế HGX sẽ được tập trung sau, với những chip B100 và B200 bên trong.
Cùng lúc, Nvidia cũng sẽ phải ra mắt trước một sản phẩm mới có tên B200A, GPU dựa trên die chip B102. Bản thân con chip này cũng chính là phiên bản mang tên B20, được Nvidia cắt giảm hiệu năng và băng thông bộ nhớ theo quy định cấm vận của Mỹ để được bán tại thị trường Trung Quốc. B102 là một nhân GPU monolithic kẹp chung với 4 die HBM RAM xung quanh. Với kích thước như vậy, Nvidia và TSMC có thể tận dụng được kỹ thuật đóng gói CoWoS-S vốn đã hoàn thiện, thay vì dựa vào CoWoS-L. Mà thậm chí nếu cần, Nvidia còn có thể đem nhân GPU B102 sang những đối tác khác như Amkor, ASE SPIL và cả Samsung để tạo ra sản phẩm thương mại.

B200A sẽ phục vụ nhu cầu điện toán với hiệu năng thấp hơn so với B100 và B200, trang bị trong những dàn máy chủ xử lý AI mức giá khởi điểm hoặc tầm trung, ví dụ như máy chủ HGX với 8 chip B200A, tối đa 144GB bộ nhớ HBM3E, tiêu thụ điện từ 700 đến 1000W mỗi máy chủ, băng thông tối đa 4TB/s.
Còn với anh em đang đợi RTX 5000 series, cũng dựa trên kiến trúc Blackwell, tất cả những rắc rối kể trên về cơ bản là không phải lo ngại, vì card đồ họa tiêu dùng với những die GPU như B103 hay B104 vẫn sẽ sử dụng thiết kế monolithic, cùng RAM GDDR6X hoặc GDDR7, không gặp những vấn đề rắc rối trong quá trình thiết kế và gia công như vì không ứng dụng kỹ thuật CoWoS-L của TSMC.