
Cách hoạt động của Stable Diffusion và những công cụ cần biết để tạo ảnh đúng ý
Để xài nó một cách chuyên sâu hơn như tùy chỉnh các tham số, rồi xài Lora, train thêm model bằng hình của chúng ta, chỉnh sửa tư thế, inpainting,…. rồi cả xài dưới local bằng sức mạnh phần cứng của chúng ta hay là đưa lên Google Collab để xài phần cứng mạnh hơn (trả phí hoặc miễn phí) Chúng ta cần biết chút xíu về cách hoạt động của Stable Diffusion, có các thành phần nào quan trọng, xin được chia sẻ sơ lược với anh em trong bài viết này.
Stable Diffusion là cái gì?
Đầu tiên thì trong machine learning có nhiều loại mô hình tạo ra dữ liệu gọi là Generative Model, trong đó lại có nhiều mô hình tạo ra hình ảnh và diffusion model là một trong số các mô hình đó. Chúng ta có thể dịch diffusion model là mô hình khuếch tán bởi bản chất hoạt động của nó là mô phỏng theo hành vi khuếch tán của phân tử (thí dụ như bạn đứng ở giữa phòng mở nắp một chai nước hoa, những người ở góc phòng vẫn sẽ có thể ngửi được mùi, đó là do các hạt được khuếch tán, lan rộng ra.)
Stable Diffusion hoạt động như thế nào?
![[IMG]](https://photo2.tinhte.vn/data/attachment-files/2024/03/8297614_1ka4ci-UymoxuH4LAjiA6iw.webp)
Checkpoint: đây chính xác là model mà chúng ta dùng, có vai trò quan trọng nhất trong hoạt động của Stable Diffusion. Một checkpoint sẽ có 2 thành phần chính là Text Encoder và Unet, có thể tạm hiểu là phần chữ và phần ảnh. Cái này anh em cứ vào https://civitai.com/ là tha hồ tải về nghịch, đủ hết.
Civitai: The Home of Open-Source Generative AI
Prompt: Cái này chính là câu lệnh dạng chữ mà người dùng nhập vào để yêu cầu model nó gen ra tấm hình như momng muốn. Những chữ này sẽ được token hóa thông qua CLIP Encoder để mô hình có thể hiểu được chúng ta đang muốn gì. Mỗi phiên bản model SD sẽ có một CLIP khác nhau, từ đó mức độ hiểu câu lệnh và làm đúng ý người dùng cũng sẽ khác nhau. Việc viết câu lệnh sao cho model nó hiểu ta muốn gì cũng cần có phương pháp một chút, cái này mình sẽ chia sẻ với anh em ở 1 bài về cách viết Prompt nha.
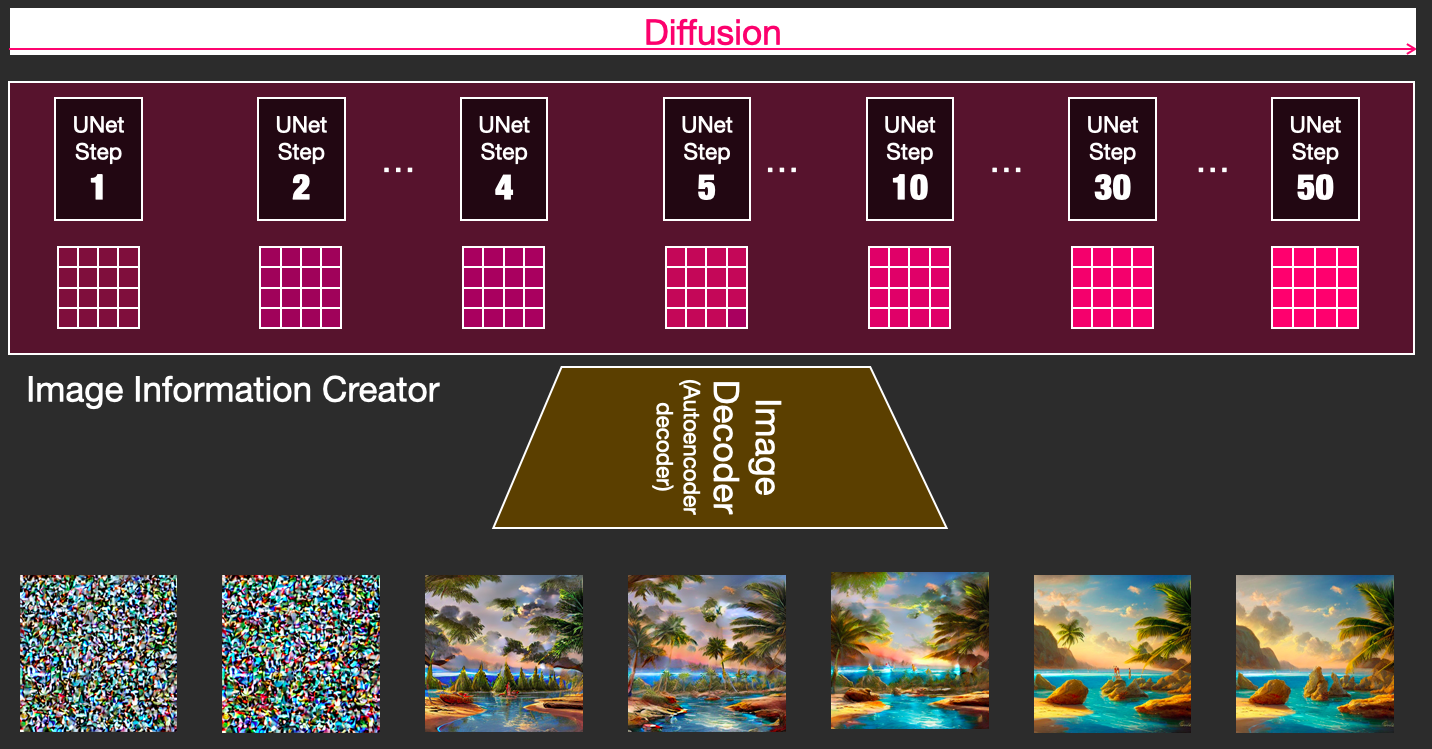
Sampler: Sau khi promtp đã được token hóa, dữ liệu đó sẽ đi qua quá trình UNET nhằm chuyển text thành hình ảnh tương ứng. Các hình ảnh đầu ra của UNET sẽ tiếp tục được gởi lặp lại quá trình n lần (gọi là step) để thêm chi tiết và hoàn thiện. Quá trình lặp lại này được gọi là Sampler – phương pháp lấy mẫu. Và có nhiều phương pháp lấy mẫu khác nhau. Anh em dùng Stable Diffusion mà thấy chỗ sampler có các tùy chọn như DPM++ 2M, DPM++ 2S a Karras, Euler,…. chính là nó đó. Mỗi cái sẽ có cách làm khác nhau và từng trường hợp sẽ có ứng dụng khác nhau. Cái này mình sẽ chia sẻ trong 1 bài khác chuyên về nó nha.
VAE: Đây là viết tắt của Variational autoencoder. Sau quá trình sampler với n steps diễn ra xong thì quá trình lấy mẫu coi như hoàn tất. Kết quả của quá trình này là một hình ảnh định dạng Latent. Anh em cứ hiểu đại khái là hình mà chúng ta nhìn qua các file JPEG, PNG,… là hình trong không gian hình ảnh image space. Thí dụ như hình đầu ra của SD 1.5 là 512x512px màu RGB, tương ứng với 1 không gian kích thước là 3 x 512 x 512, đây là cái mà chúng ta không thể bắt model chạy trên máy local được. Và trong momdel latent diffusion thì giải pháp ở đây là nén không gian đó về thành một latent nhỏ hơn 64 lần, chỉ là 3x64x64. Đây chính là cái mà Sampler đã tạo ra đó. VAE sẽ có nhiệm vụ “tăng độ phân giải” để trả cho bạn hình đầu ra bằng cách sử dụng các “model con”. Quá trình này sẽ “dựng” các chi tiết trong hình như mắt, mũi, miệng, áo, quần,… đã được train sẵn để trả về kết quả cuối cùng là tấm hình anh em muốn.
Xong, coi như trên đây là 4 bước, 4 thành phần quan trọng nhất mà một model nó chạy trong Stable Diffusion để trả về hình ảnh mà chúng ta ra lệnh cho nó.
Những công cụ cơ bản để tăng độ đúng ý khi tạo ảnh
Tuy nhiên, 4 thành phần này vẫn chưa đủ chi tiết để phục vụ nhu cầu đa dạng và chi tiết của chúng ta. Và vì thế, người ta làm thêm các “tùy chọn/công cụ/extension” như bên dưới:

Lora: có thể hiểu đây là một “model con”, nhỏ hơn checkpoint, để bổ sung dữ liệu về TexEncoder và UNET về một nhánh chủ đề hình ảnh đặc thù nào đó thí dụ như một concept ảnh, chất liệu sản phẩm, Pose mẫu, quần áo,…
Embedding: đây cũng là một thành phần như Lora nhưng chỉ bổ sung khái niệm mới vào Text Encoder để hiểu được nhiều từ ngữ đặc biệt trong prompt. Embedding chỉ đụng vô text encoder, không đụng vào UNET.
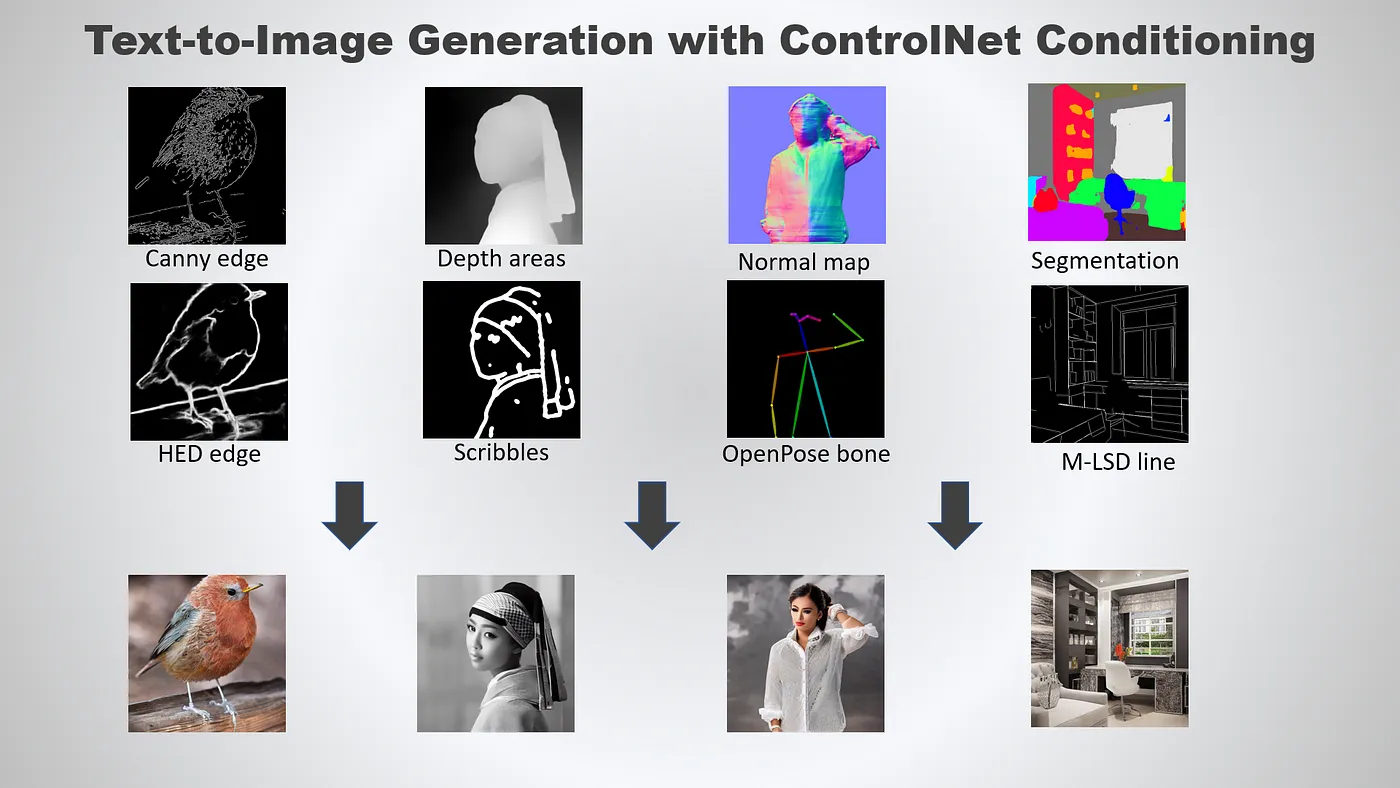
Controlnet: Sẽ có nhiều bức ảnh anh em muốn bắt model tạo ra nhưng rất khó để miêu tả bằng text, thí dụ như bố cục hình ảnh, tư thế pose của mẫu, độ sâu trong một không gian nội thất, thứ tự sắp xếp các vật thể trong phòng, biểu cảm của một nhân vật anime,… Lúc này, chúng ta sẽ dùng các Controlnet để ra lệnh kèm với text thông thường.
Một số nguồn Controlnet tham khảo:
- Controlnet WebUI Automatic1111
- T2I-Adapter
- IP-Adapter
- Control Lora

Inpainting: công cụ này dùng để gen hình từ một tấm hình đã có sẵn, chỉnh sửa các thành phần cụ thể trên một ảnh trước đó do AI gen ra, thêm bớt yếu tố vào ảnh,… Mặc định trong model Stable Diffusion đã có sẵn Inpainting, tuy nhiên nếu xài các model inpainting và controlnet inpainting riêng thì sẽ chính xác và ngon hơn.
Rồi coi như tới đây thì chúng ta đã nắm được hầu hết các thành phần và cách quan trọng để tạo ra ảnh theo đúng ý muốn. Từng cái đó lại có những chi tiết thủ thuật sử dụng để đạt hiệu quả cao nhất, sau đó là phối hợp các công cụ để hình thành nên một workflow tạo ảnh để phục vụ nhu cầu của chúng ta.
Chi tiết hơn cách hoạt động của Stable Diffusion
Phần này mình định viết ở đây luôn mà thấy bài dài quá thể rồi, thôi mình hẹn anh em bài khác do bài này sẽ lùm xùm về bản chất hoạt động của model, rồi cách nó chạy dưới ngôn ngữ của khoa học máy tính. Hẹn anh em sau vậy.